5 Database Normalization Forms

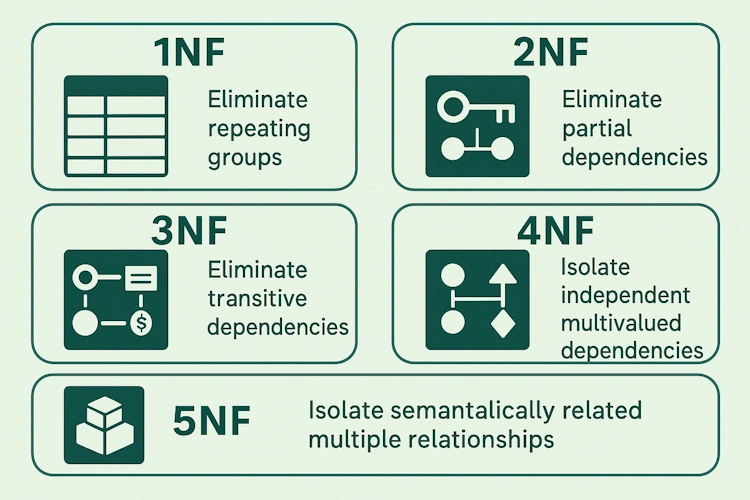
What is normalization
Normalization is the process of structuring relational tables so that each fact is stored once and all dependencies are explicit. In practice, you:
- Identify functional dependencies.
- Choose candidate keys, minimal columns that uniquely identify a row.
- Split tables so that non‑key attributes depend only on a key, the whole key, and nothing but the key.
Why we need it:
- Avoid update, insert, and delete anomalies.
- Enforce data integrity with foreign keys instead of application discipline.
- Reduce duplication, which saves storage and reduces bugs.
- Make business rules obvious by putting each truth in one place.
- Trade‑offs: more joins on reads. Solve this using indexes, read models, and materialized views for hot paths, while maintaining the source of truth in a normalized state.
Why normalization at all?
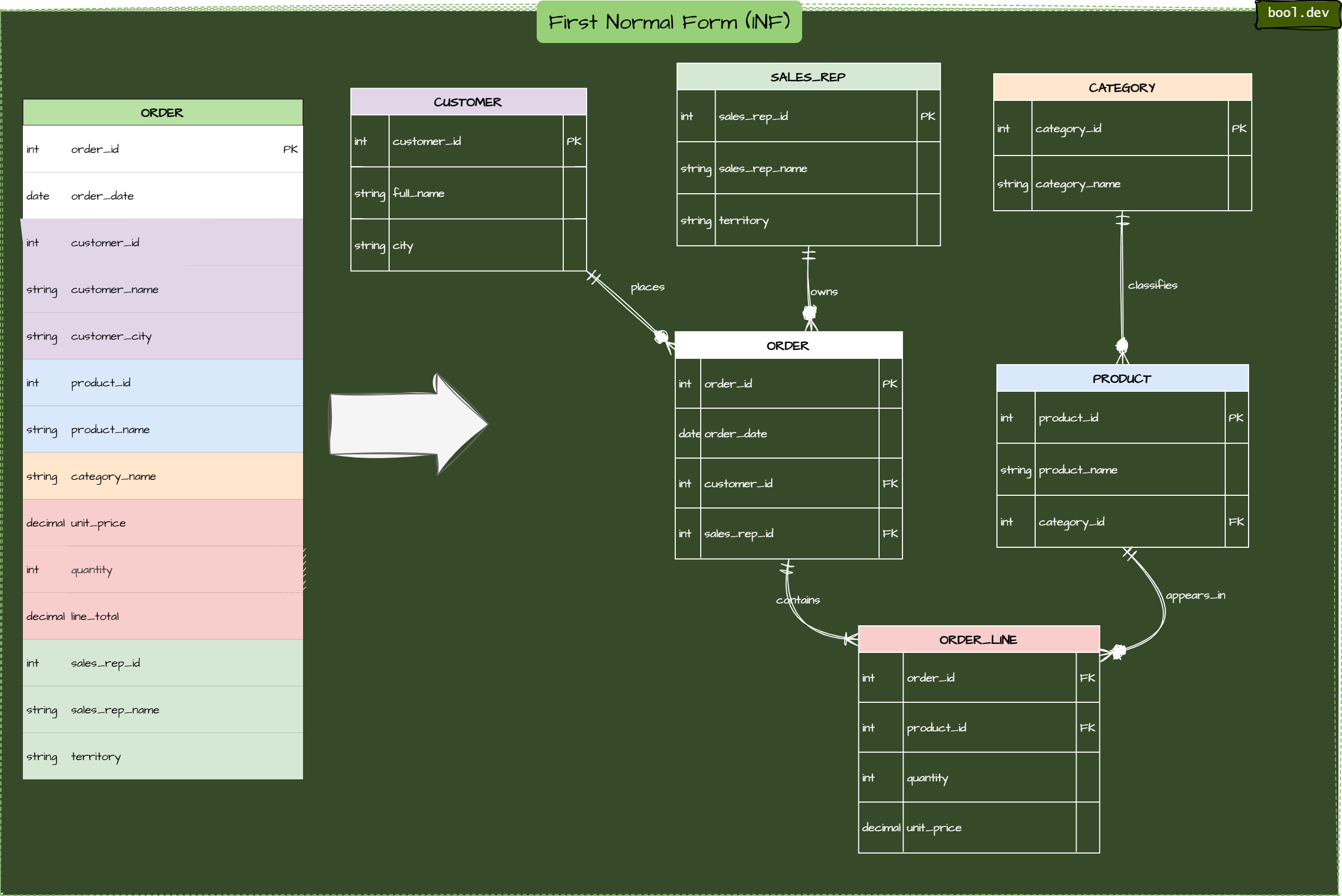
Without normalization, a single update can turn into a whack‑a‑mole situation. Consider an Online Retail app storing orders like this:
Orders(order_id, order_date, customer_id, customer_name, customer_city,
product_id, product_name, category_name, unit_price,
quantity, line_total, sales_rep_id, sales_rep_name, territory)Problems:
- Update anomaly: Change
customer_city— How many rows to touch? - Insert anomaly: You can’t add a new product before it appears in an order.
- Delete anomaly: Deleting an order might “forget” a product or a sales rep.
- Normalization eliminates these by restructuring tables so that each fact lives in exactly one place.
First Normal Form (1NF)
keep it atomic, separate repeating groups
- No arrays or CSV in a cell (for example,
phones = '…;…'). - Each row/column intersection holds a single value.
- Repeating groups (line items) go to their own table.
How to recognize 1NF violations
- Cells that contain lists (commas, JSON, arrays) or repeating columns like
phone1, phone2, phone3. - Tables that mix header facts (order) and line facts (items) in one row.
Example of quick SQL smell tests
-- list‑like values in a single column
SELECT * FROM customer WHERE phone LIKE '%,%' OR phone LIKE '%;%' ;
-- repeating columns in DDL
-- manual review: phone1, phone2, ... => move to CUSTOMER_PHONE1NF Example:
Second Normal Form (2NF)
A table is supposed to be in 2NF if,
- It is in the 1st normal form.
- It does not have any partial dependency
How to recognize 2NF violations
- For each composite‑key table, pick a non‑key
column C. - Ask: Does some subset of the key determine
C? For example,product_iddeterminesproduct_name. - If yes, move
Cto the table keyed by that subset.
2NF Example:
We have the following Employee table:
| Employee id | Department Id | Employee Name | Department Name |
|---|---|---|---|
| 1 | 21 | John Doe | IT |
| 2 | 22 | Jessica Alba | Marketing |
Let's transform it into 2NF:
Employee table:
| id | Department Id | Name |
|---|---|---|
| 1 | 21 | John Doe |
| 2 | 22 | Jessica Alba |
Department table:
| Department Id | Department Name |
|---|---|
| 21 | IT |
| 22 | Marketing |
Third Normal Form (3NF)
A table is supposed to be in third normal form if,
- It satisfies the 2nd normal form.
- It does not have any transitive dependencies.
Said, the 2NF requires moving all non-key fields, whose contents may relate to several table records, into separate tables.
3NF Example:
Consider the table:
| Car model | Store | Phone number |
|---|---|---|
| BMW | Golden Gate | 555-22-74 |
| Volvo | Volvo West | 555-13-17 |
| Mercedes | Golden Gate | 555-22-74 |
The table is in Second Normal Form (2NF) but not in Third Normal Form (3NF). The attribute "Car Model" serves as the primary key. Cars do not possess personal phones; instead, the phone number is dependent solely on the store. Consequently, the following functional dependencies exist: Car Model > Store, Store > Phone, and Model > Phone.
Since the dependency Model > Phone is transitive, the relation does not meet the criteria for 3NF.
Below is an example of how we can transform this table to meet 3NF requirements:
| Store | Phone number |
|---|---|
| Golden Gate | 555-22-74 |
| Volvo West | 555-22-74 |
| Car model | Store |
|---|---|
| BMW | Golden Gate |
| Volvo | Volvo West |
| Mercedes | Golden Gate |
Boyce and Codd Normal Form (BCNF)
3NF is not always enough. If any determinant (left side of a functional dependency) is not a candidate key, you have a BCNF violation.
BCNF Example:
Example (Sales): Each Sales Rep works in exactly one Territory. Table tracking rep–client assignments:
REP_CLIENT(rep_id PK part, client_id PK part, territory)Dependencies: rep_id determines territory, but the key is (rep_id, client_id). So rep_id (not a key) determines territory, so this is a BCNF violation.
Fix: split the territory to REP_TERRITORY.
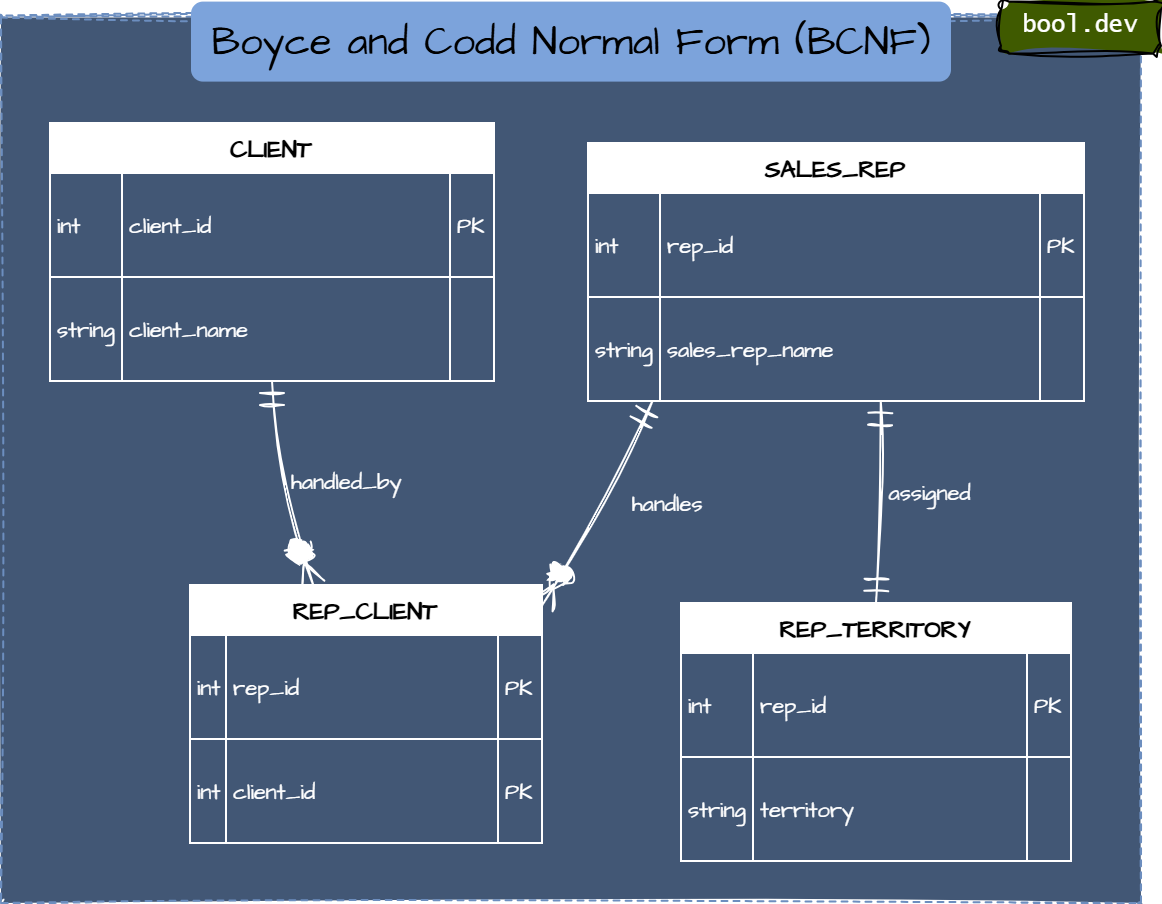
Result: No non‑key determinant remains inside a table.
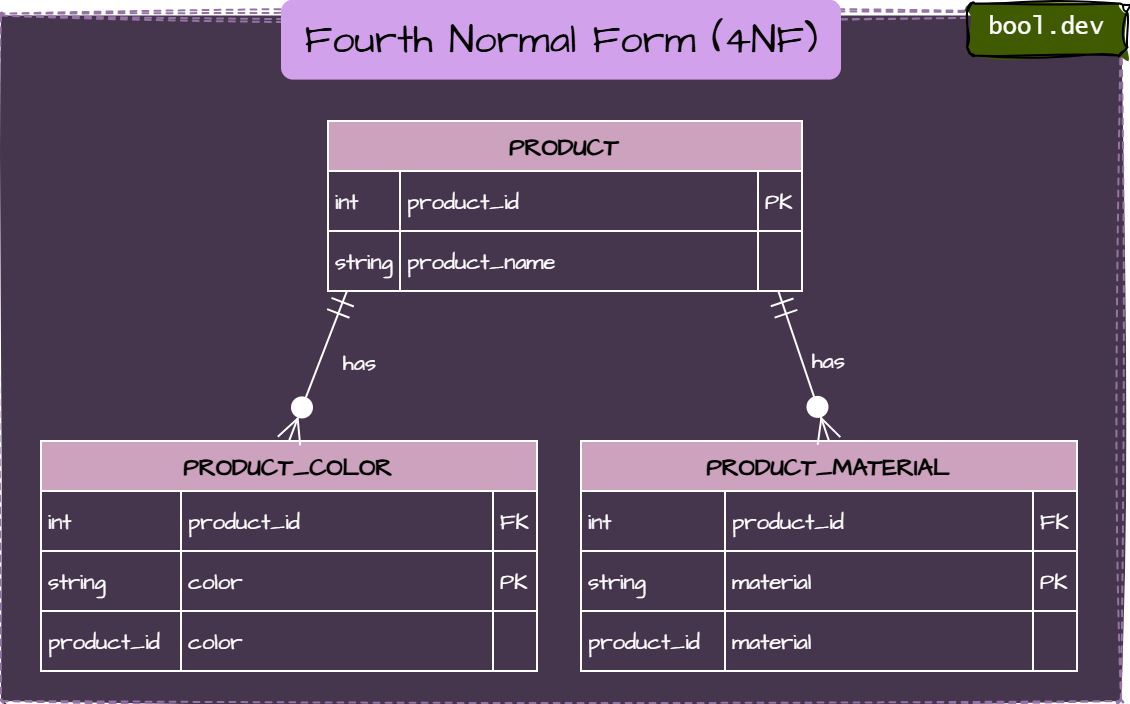
Fourth Normal Form (4NF)
A table is supposed to be in fourth normal form if,
- It is in BCNF.
- A table stores two or more independent lists for the same key:
- Two attributes vary independently for the same key.
- The cross‑product of the lists creates spurious (non‑real) combinations.
4NF example:
Example (Catalog): A product can come in multiple colors and multiple materials, and these choices are independent.
PRODUCT_OPTION(product_id, color, material)This implies combinations that may not exist (for example, Blue + Titanium) and duplicates facts.
Fix: Split into two tables.
Five Normal Form (5NF)
The highest level of normalization is also known as Project-Join Normal Form (PJNF). It is used to handle many-to-many relationships in a database.
A table is supposed to be in 5NF if,
- It is in the 4th normal form.
- 5NF is achieved when a table is in 4NF and all join dependencies are removed. This form ensures that every table is fully decomposed into smaller tables that are logically connected without losing information.
5NF Example:
Example: If a table contains (StudentID, Course, Instructor) and there is a dependency where all combinations of these columns are needed for a specific relationship, you would split them into smaller tables to remove redundancy.
When denormalization makes sense
Normalization removes anomalies and clarifies ownership. Denormalization is a pragmatic, read‑optimized copy of some facts. Use it when measurements show it pays off.
Common reasons
- Read-heavy endpoints, such as product listings, feeds, and dashboards, with many joins.
- Aggregates that are expensive to compute repeatedly, such as order totals or monthly counts.
- Locality of reference when attributes are always read together, and you want fewer disk seeks or network round‑trips.
- Partition alignment to avoid cross‑partition joins in sharded systems.
- Reporting snapshots: slowly changing dimensions, historical prices at the time of purchase.
- Availability and resilience: precomputed read models for offline or degraded‑mode queries.
Safe patterns
- Materialized views with a refresh schedule or event‑driven refresh.
- Read models and projections in CQRS or event‑sourced systems.
- Cached denormalized JSON next to normalized truth, limited to what you actually index and query.
- Duplicate columns with a clear owner and validation (generated columns, triggers, or application checks).
- Values that should never change retroactively, like
unit_priceortax_ratecaptured at order time.
Guardrails
- Keep the normalized source as the authority.
- Document ownership and refresh rules, and cover them with tests.
- Make backfills and replays idempotent.
- Monitor drift between copies with periodic checks.
Tiny example Keep order_total in the orders table and update it when order lines change. Treat it as a cache of the sum of quantity multiplied by unit_price. For analytics, expose a materialized view with daily rolled‑up totals.