C# Async & Parallel Programming – .NET Interview Questions and Answers


Welcome to the our .NET Interview Questions and Answers series exploring the ins and outs of C# and .NET! This chapter explores advanced asynchronous and parallel programming in .NET, including Tasks, Thread Pools, channels, race conditions, context switches, and best practices.
The Answers are split into sections: What 👼 Junior, 🎓 Middle, and 👑 Senior .NET engineers should know about a particular topic.
Also, please take a look at other articles in the series: C# / .NET Interview Questions and Answers
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 3: Collections and Data Structures
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 7: SQL Database
- Part 8: NoSQL Databases
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI
- Part 14: Agile & Scrum
Core Asynchrony & Task-Based Programming

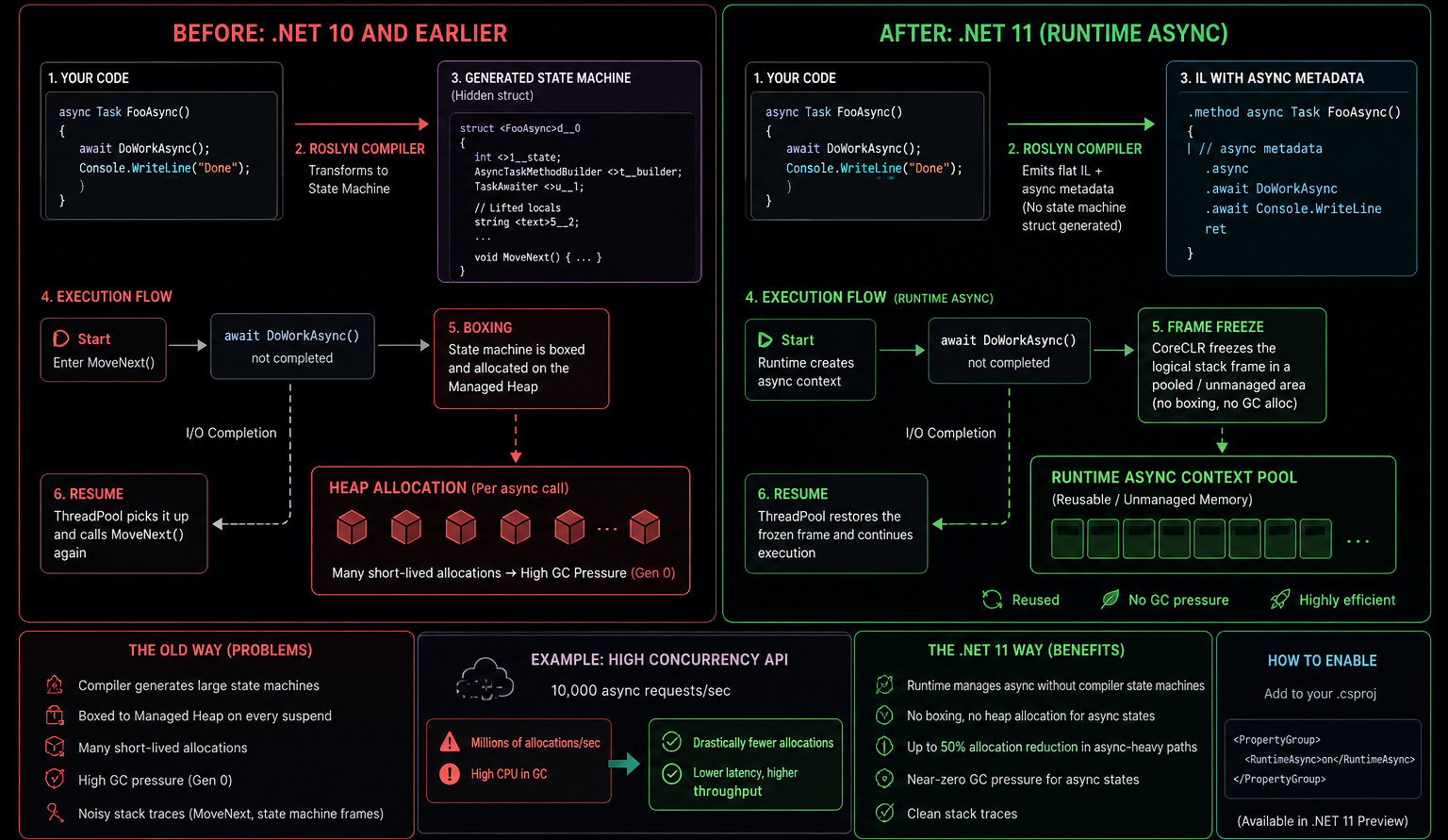
❓ What is Runtime Async in .NET 11, and how does it differ from the traditional async/await implementation?
Since C# 5, asynchronous methods have been implemented primarily by the compiler. When you write an async method, the compiler rewrites it into a hidden state machine that tracks execution progress across await points.
public async Task<string> GetDataAsync()
{
await Task.Delay(100);
return "Done";
}is transformed into a generated state machine with a MoveNext() method and several compiler-generated fields used to preserve local variables and execution state.
This approach works well, but it has drawbacks:
- Additional allocations
- Extra GC pressure
- Complex stack traces
- Compiler-generated state machine overhead
In .NET 11, Microsoft introduced Runtime Async, which moves much of the async execution machinery from the C# compiler into the CoreCLR runtime itself. Instead of generating large state machines for every async method, the runtime directly manages suspension and resumption of asynchronous execution.
The runtime now understands async methods as a first-class execution model.
Benefits include:
- Reduced allocations
- Lower GC pressure
- Cleaner stack traces
- Better throughput in heavily asynchronous applications
- Better integration with JIT optimizations
- Support for Native AOT and ReadyToRun scenarios
This is one of the biggest architectural changes to the .NET async engine since the introduction of async and await in C# 5.
What .NET engineers should know
- 👼 Junior: Understand that async methods historically compile into state machines and that Runtime Async reduces the overhead of those state machines automatically. Existing async code continues to work without modification.
- 🎓 Middle: Understand where async allocations come from and why reducing them improves throughput, latency, and scalability in web APIs and background services.
- 👑 Senior Understand how Runtime Async changes the architecture of async execution inside CoreCLR, how it affects GC behavior and performance under load, and how it interacts with JIT, PGO, Native AOT, and cloud-native workloads.
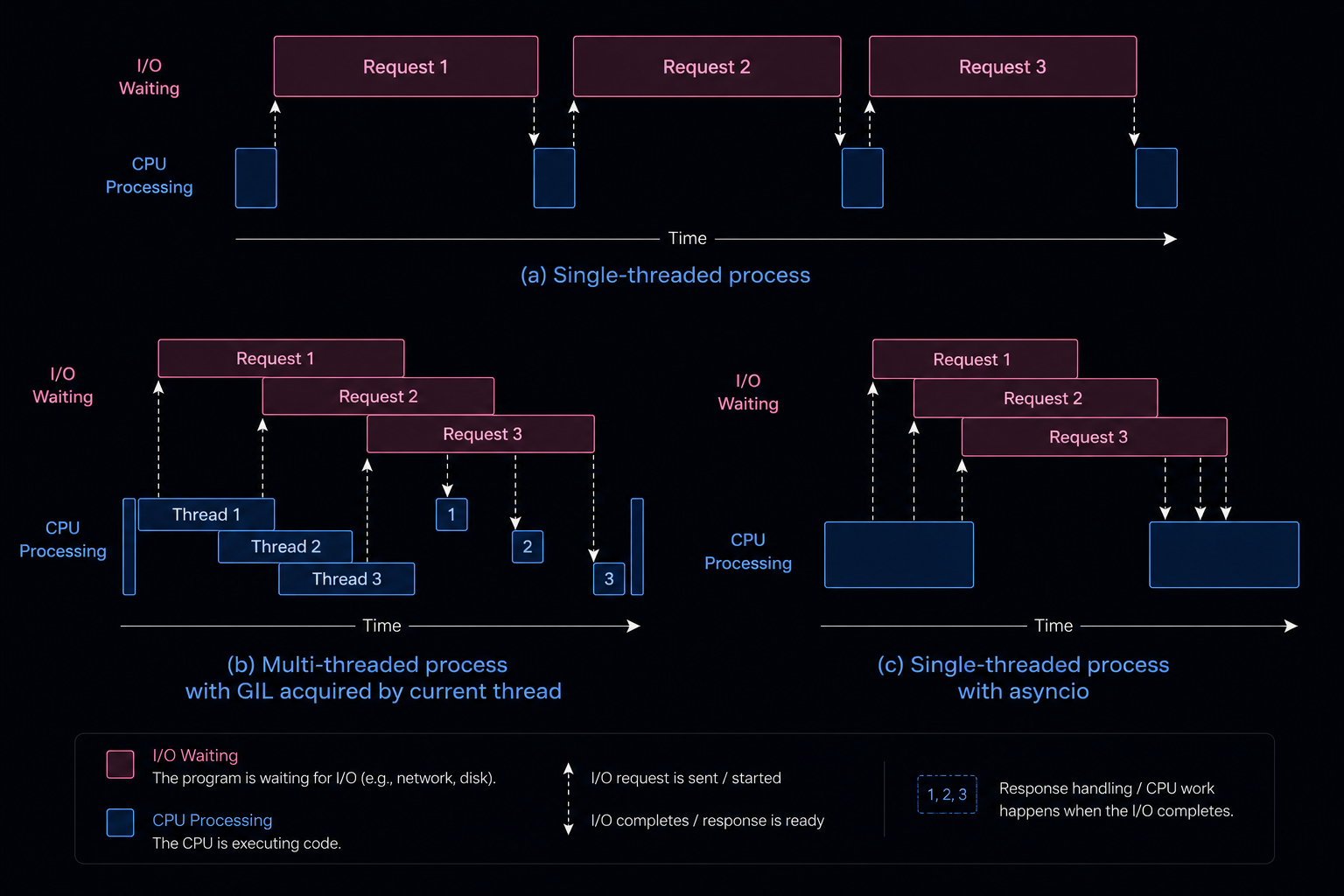
❓ What is the difference between asynchronous programming using async/await and traditional multithreading?
Asynchronous programming with async/await your application can efficiently handle operations that wait for external resources (like database calls, network requests, or file I/O) without blocking the main thread. Unlike traditional multithreading, it doesn't necessarily spin up new threads—instead, it frees existing threads to perform other tasks while waiting.
Example:
// Async-await example
public async Task<string> FetchDataAsync(string url)
{
using var client = new HttpClient();
return await client.GetStringAsync(url); // non-blocking
}
// Traditional multithreading example using Task
public string FetchDataWithTask(string url)
{
return Task.Run(async () =>
{
using var client = new HttpClient();
return await client.GetStringAsync(url).ConfigureAwait(false); // Avoid capturing context
}).Result;
}What .NET engineers should know:
- 👼 Junior: Understand that
async/awaitkeeps applications responsive by not blocking the main thread during long-running operations. - 🎓 Middle: Know when and how to use
async/awaitfor I/O-bound tasks, recognizing it does not inherently create additional threads like traditional multithreading. - 👑 Senior: Grasp the underlying mechanisms of asynchronous programming, including context capturing, synchronization contexts, and when multithreading might still be beneficial (CPU-bound tasks).
📚Resources: Async/Await in .NET
❓ What is the relationship between a Task and the .NET ThreadPool?
A Task represents an asynchronous operation that may or may not execute on a thread. When tasks involve CPU-bound operations, they typically run on the .NET ThreadPool. The ThreadPool manages threads efficiently, dynamically adjusting the number of active threads based on workload, system resources, and thread availability.
Example:
Task.Run(() =>
{
// CPU-bound operation
Console.WriteLine($"Running on thread {Thread.CurrentThread.ManagedThreadId}");
});What .NET engineers should know:
- 👼 Junior: Recognize that tasks may run on ThreadPool threads, managed automatically by the runtime.
- 🎓 Middle: Understand how tasks and the ThreadPool interact, particularly that the runtime manages thread lifecycle and concurrency levels based on workload and heuristics.
- 👑 Senior: Know details about ThreadPool's adaptive thread injection and hill-climbing algorithm for optimal performance, including when to adjust settings manually.
📚Resources: Understanding the .NET ThreadPool
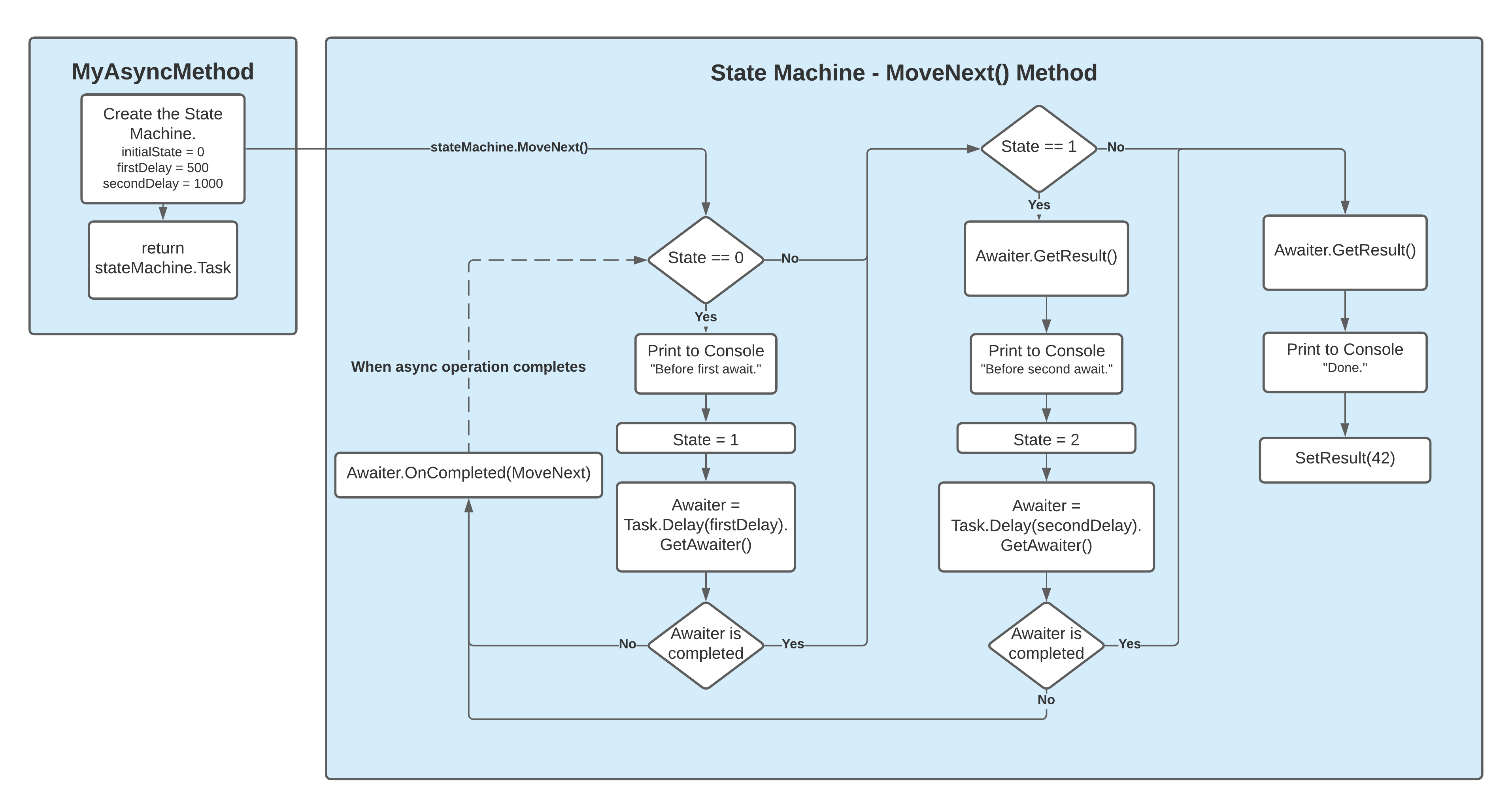
❓ How does the C# compiler transform an async method under the hood (state-machine generation, captured context, etc.)?
The C# compiler converts async methods into a state machine behind the scenes. Each await becomes a checkpoint within this state machine, capturing the method's state and the synchronization context, allowing execution to pause and resume seamlessly without blocking the calling thread.
Example:
public static async Task<int> MyAsyncMethod(int firstDelay, int secondDelay)
{
Console.WriteLine("Before first await.");
await Task.Delay(firstDelay);
Console.WriteLine("Before second await.");
await Task.Delay(secondDelay);
Console.WriteLine("Done.");
return 42;
}
What .NET engineers should know:
- 👼 Junior: Know that async methods are compiled into special structures that allow pausing and resuming execution smoothly.
- 🎓 Middle: Understand how the compiler generates a state machine, handling await points, captured variables, and contexts automatically.
- 👑 Senior: Be familiar with the generated IL code, recognize potential pitfalls like unnecessary context capturing (using
ConfigureAwait(false)), and optimize async performance.
📚Resources:
- Exploring the async/await State Machine – Main Workflow and State Transitions
- How Async/Await works under the hood
- Understanding async state machines
❓ Explain the purpose of SynchronizationContext and how it affects continuation scheduling in async/await
SynchronizationContext is an abstraction that allows code to schedule tasks on a specific execution environment, such as a UI thread in desktop applications or a request thread in ASP.NET. When using async/await, it ensures continuations after an await resume on the correct thread, maintaining thread affinity and preventing concurrency issues.
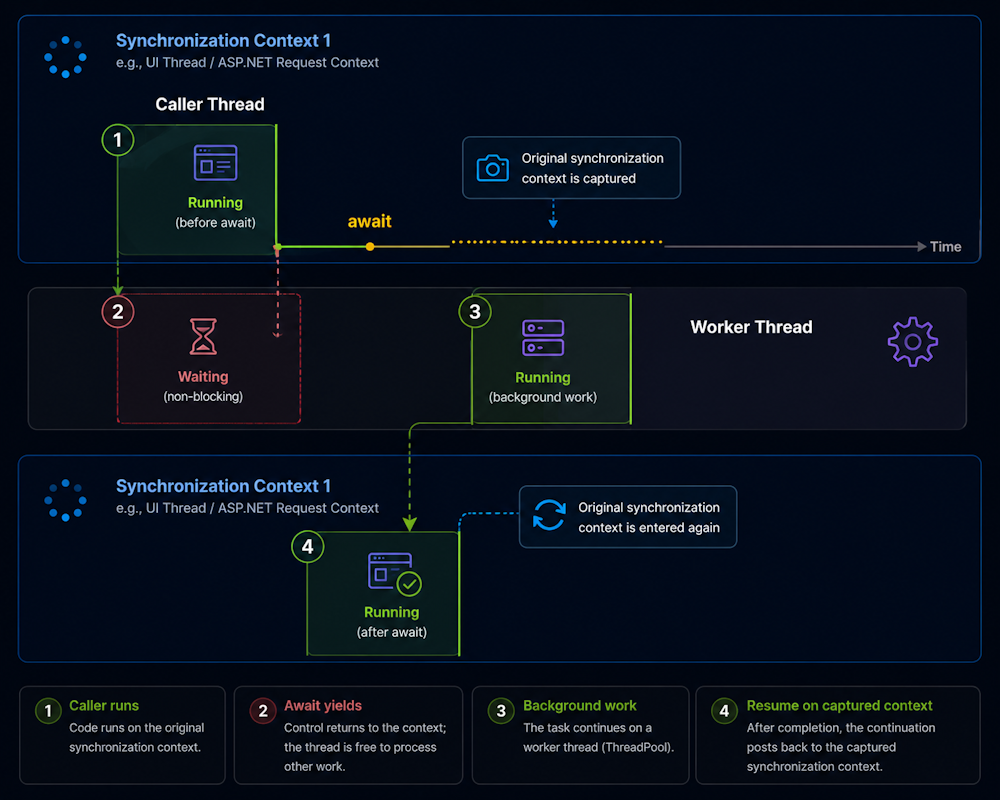
For example, in UI applications such as WPF or WinForms, the synchronization context ensures that UI updates occur safely on the UI thread after asynchronous tasks are completed.
// WPF application example
private async void Button_Click(object sender, RoutedEventArgs e)
{
await Task.Delay(1000); // Simulate async work
MyTextBox.Text = "Updated!"; // Resumes on UI thread
}
// Using ConfigureAwait(false) to avoid capturing context
private async Task DoBackgroundWorkAsync()
{
await Task.Delay(1000).ConfigureAwait(false);
// Continuation may run on a ThreadPool thread
}What .NET engineers should know:
- 👼 Junior: Understand that
SynchronizationContexthelps async continuations run on the original thread (e.g., UI thread), preventing common threading issues in UI scenarios. - 🎓 Middle: Know when and how to use
.ConfigureAwait(false)To avoid unnecessary context capture, improve performance, especially in library code or server-side scenarios. - 👑 Senior: Have deep insights into how different frameworks (WPF, WinForms, ASP.NET, Console apps) implement synchronization contexts, their impacts on scalability, and strategies for optimal async design.
📚 Resources:
❓ What problems can arise if you mix synchronous blocking (Task.Wait, .Result) with asynchronous code, and how do you avoid them?
Mixing synchronous blocking methods (Task.Wait() or .Result) with asynchronous code, can cause deadlocks, especially in environments with a synchronization context like UI apps (WPF, WinForms) or older ASP.NET applications. These blocking calls halt the current thread, waiting for an async task to finish. If that async task tries to resume on the blocked thread, both end up waiting indefinitely—a classic deadlock scenario.
Example of problematic code causing a deadlock:
// This can cause a deadlock in UI apps
public void Button_Click(object sender, EventArgs e)
{
// Blocking call (.Result) waiting for async method
var result = FetchDataAsync().Result;
MessageBox.Show(result);
}
public async Task<string> FetchDataAsync()
{
await Task.Delay(1000); // Simulate async operation
return "Done";
}How to avoid these problems:
- Always use
awaitwith async methods instead of.Resultor.Wait()in contexts supporting asynchronous execution. - If synchronous calls can't be avoided, ensure async methods use
.ConfigureAwait(false)to prevent capturing the synchronization context.
Safe corrected example:
// Proper async usage in UI
public async void Button_Click(object sender, EventArgs e)
{
var result = await FetchDataAsync();
MessageBox.Show(result);
}
// Async method adjusted to avoid context capturing (good practice for libraries)
public async Task<string> FetchDataAsync()
{
await Task.Delay(1000).ConfigureAwait(false);
return "Done";
}What .NET engineers should know:
- 👼 Junior: Know that calling
.Resultor.Wait()on asynchronous tasks can cause your application to freeze or deadlock, particularly in UI apps. - 🎓 Middle: Recognize common scenarios where deadlocks can occur, and consistently use
awaitor.ConfigureAwait(false)appropriately to prevent context capturing when necessary. - 👑 Senior: Understand how synchronization contexts and continuations interact, proactively designing APIs that discourage synchronous blocking and guiding teams toward safe async usage patterns.
📚 Resources:
❓ How does TaskCompletionSource let you wrap callback-based APIs as tasks, and what pitfalls should you watch for?
TaskCompletionSource helps you bridge traditional callback-based APIs to modern async Task-based methods in .NET. It provides a simple way to manually create, complete, or fault a Task, making it ideal for wrapping legacy or third-party asynchronous APIs.
Example of wrapping a callback API with TaskCompletionSource:
// Simulated legacy callback API
void LegacyApi(Action<string> onSuccess, Action<Exception> onError)
{
try
{
// Simulate async operation
ThreadPool.QueueUserWorkItem(_ =>
{
Thread.Sleep(1000);
onSuccess("Operation succeeded!");
});
}
catch (Exception ex)
{
onError(ex);
}
}
// Wrapped using TaskCompletionSource
public Task<string> WrappedLegacyApiAsync()
{
var tcs = new TaskCompletionSource<string>();
LegacyApi(
result => tcs.SetResult(result),
ex => tcs.SetException(ex)
);
return tcs.Task;
}Common pitfalls:
- Always handle exceptions properly; forgetting
SetExceptionleaves tasks incomplete. - Ensure that the task completes exactly once, calling
SetResultorSetExceptionmultiple times leads to runtime exceptions. - Avoid calling
.Resultor.Wait()on tasks created byTaskCompletionSourcein UI or synchronization-context scenarios.
What .NET engineers should know:
- 👼 Junior: Understand that
TaskCompletionSourcehelps wrap non-task asynchronous patterns (callbacks/events) intoTask-based methods. - 🎓 Middle: Confidently use
TaskCompletionSourceto modernize legacy APIs, carefully handling task completion and exceptions. - 👑 Senior: Be aware of advanced scenarios such as ensuring thread-safety, managing task cancellation using
SetCanceled, and properly configuring continuation behaviors.
📚 Resources:
- Using TaskCompletionSource
- Task-based Asynchronous Pattern (TAP)
- [RU] Async programming in .NET: Best practices
❓ What are fire-and-forget tasks, why are they risky, and how can you safely monitor/handle their failures?
A fire-and-forget task is an asynchronous operation started without awaiting or monitoring its completion. This pattern can seem convenient when results aren't immediately needed, but it introduces risks such as unhandled exceptions and application instability, as failures often go unnoticed.
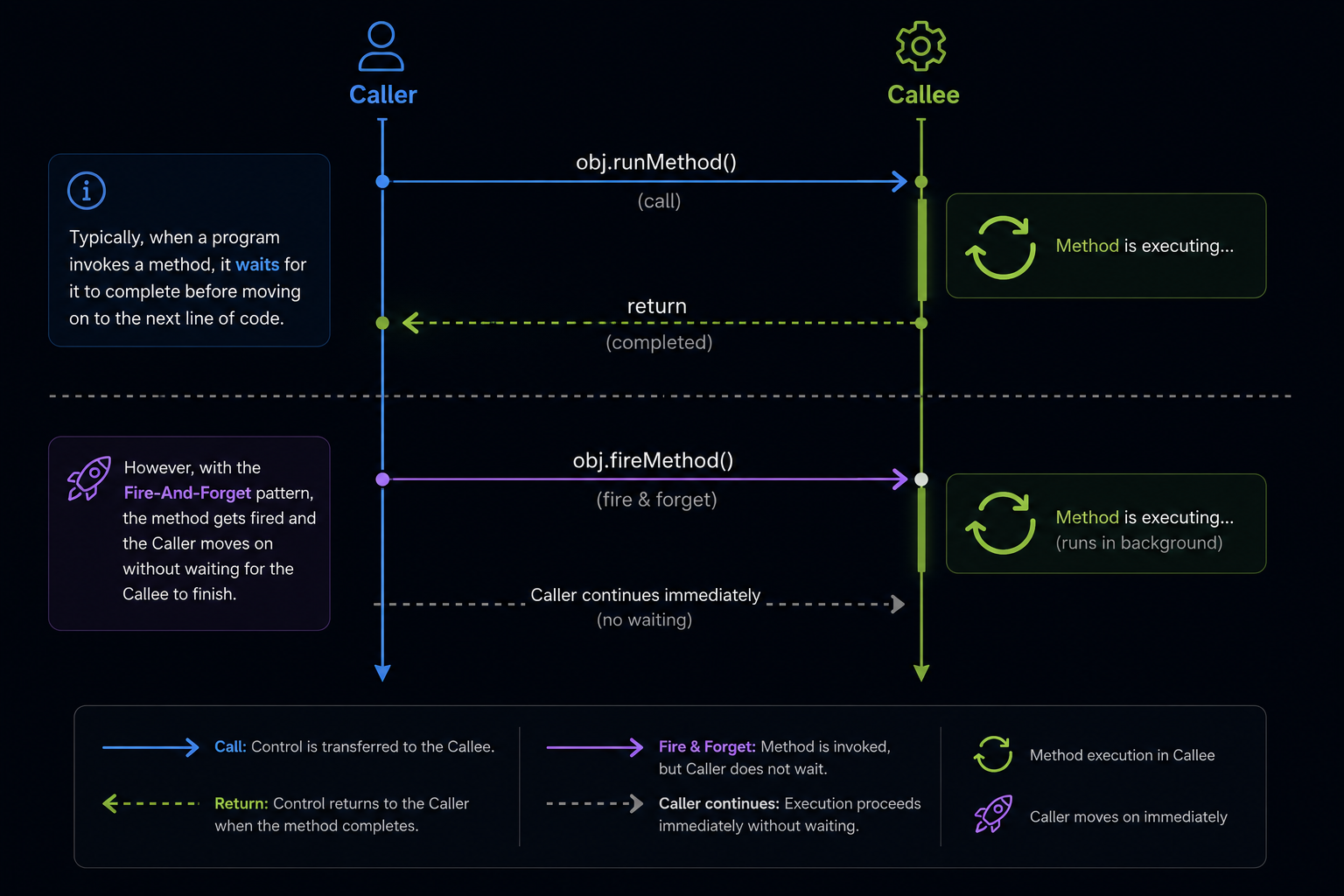
Risks of fire-and-forget tasks:
- Exceptions thrown within these tasks may be silently ignored, resulting in unpredictable behavior.
- Issues such as resource leaks or inconsistent states can occur unnoticed.
Example of a risky fire-and-forget task:
// risky fire-and-forget example
void DoWork()
{
Task.Run(async () =>
{
await Task.Delay(1000);
throw new Exception("Oops!");
});
// exception goes unnoticed!
}How to safely handle fire-and-forget tasks:
- Use a dedicated wrapper method to log and handle exceptions explicitly.
- Attach a global handler via
TaskScheduler.UnobservedTaskExceptionto catch any unobserved exceptions. - Use continuations with
.ContinueWith()or a helper method to observe exceptions.
Safe handling example:
// Safe fire-and-forget method
public void SafeFireAndForget(Func<Task> asyncMethod)
{
// Register global unobserved task exception handler (typically done once at app startup)
TaskScheduler.UnobservedTaskException += (sender, e) =>
{
Console.WriteLine($"Unobserved task exception: {e.Exception.Message}");
e.SetObserved(); // Mark as handled to prevent escalation
};
Task.Run(async () =>
{
try
{
await asyncMethod();
}
catch (Exception ex)
{
// Handle or log the exception here
Console.WriteLine($"Exception caught: {ex.Message}");
}
});
}
// Usage
void DoWork()
{
SafeFireAndForget(async () =>
{
await Task.Delay(1000);
throw new Exception("Oops, safely handled!");
});
}What .NET engineers should know:
- 👼 Junior: Understand that fire-and-forget tasks execute independently, and know the dangers of unhandled exceptions going unnoticed, leading to silent failures.
- 🎓 Middle: Implement safe wrappers or continuation handlers to manage exceptions effectively and prevent silent failures. Be aware of
TaskScheduler.UnobservedTaskExceptionfor global monitoring. - 👑 Senior: Design robust mechanisms (e.g., centralized logging, global error handlers like
TaskScheduler.UnobservedTaskException, or monitoring solutions) to manage fire-and-forget tasks in production environments.
📚 Resources:
❓ What is the difference between Task and ValueTask in asynchronous programming, and when should you prefer one over the other?
Task and ValueTask both represent asynchronous operations in .NET, but they differ primarily in allocation behavior and performance characteristics:
Task
Task a reference type (class). Creating a new Task Always involves heap allocation, which incurs some performance overhead, particularly when used frequently in performance-critical scenarios.
Example:
public async Task<int> GetDataAsync()
{
await Task.Delay(1000);
return 42;
}When to use a task:
- For most general-purpose asynchronous methods.
- When your async methods always or usually run asynchronously.
- When simplicity and compatibility outweigh the minor performance benefits.
ValueTask
ValueTask a value type (struct) designed to avoid unnecessary heap allocations. It’s beneficial when methods frequently complete synchronously, reducing GC overhead and improving performance.
Example:
private readonly Dictionary<int, string> _cache = new();
public ValueTask<string> GetCachedValueAsync(int id)
{
if (_cache.TryGetValue(id, out var result))
{
// Returns synchronously without allocation
return new ValueTask<string>(result);
}
// Otherwise fall back to async method
return new ValueTask<string>(LoadFromDbAsync(id));
}
private async Task<string> LoadFromDbAsync(int id)
{
await Task.Delay(1000); // simulate DB fetch
return "value from DB";
}When to use ValueTask:
- In performance-sensitive code paths, particularly when methods may often complete synchronously.
- When optimizing hot paths to reduce garbage collection overhead.
What .NET engineers should know:
- 👼 Junior: Recognize that
ValueTaskis a lightweight alternative toTask, useful for performance-sensitive scenarios. - 🎓 Middle: Know when and how to apply
ValueTaskin code to reduce unnecessary memory allocation, especially in methods likely to complete synchronously. - 👑 Senior: Understand the deeper implications of using
ValueTask, including avoiding pitfalls like multiple awaits (which may be unsafe withValueTask) and ensuring proper usage patterns.
📚 Resources:
❓ How do you cancel an asynchronous operation in .NET, and what are best practices for using cancellation tokens?
Cancellation in asynchronous methods is managed in .NET via the CancellationToken structure. Proper cancellation enhances application responsiveness and resource management by allowing tasks to terminate gracefully when they are no longer needed.
Key points for implementing cancellation:
- Use
CancellationTokenparameters in methods supporting cancellation. - Check
token.IsCancellationRequestedperiodically in long-running tasks. - Throw
OperationCanceledException(token)to signal that the operation was canceled. - Pass tokens down to built-in async methods that accept them (like
Task.Delay,HttpClientmethods, file streams, etc.). - Dispose of
CancellationTokenSourcewhen it's no longer needed.
Example of basic cancellation usage:
public async Task PerformOperationAsync(CancellationToken token)
{
for (int i = 0; i < 10; i++)
{
token.ThrowIfCancellationRequested();
await Task.Delay(1000, token); // Pass token to built-in methods
Console.WriteLine($"Completed iteration {i}");
}
}
var cts = new CancellationTokenSource();
try
{
// Cancel after 3 seconds
cts.CancelAfter(TimeSpan.FromSeconds(3));
await PerformOperationAsync(cts.Token);
}
catch (OperationCanceledException)
{
Console.WriteLine("Operation was cancelled.");
}
finally
{
cts.Dispose();
}
Advanced patterns and best practices:
- Linking CancellationTokenSources: When multiple sources may trigger cancellation (e.g., timeout, manual user input), use linked tokens:
using var timeoutCts = new CancellationTokenSource(TimeSpan.FromSeconds(30));
using var userCts = new CancellationTokenSource();
using var linkedCts = CancellationTokenSource.CreateLinkedTokenSource(timeoutCts.Token, userCts.Token);
await PerformOperationAsync(linkedCts.Token);
- Prefer polling with
token.ThrowIfCancellationRequested()for responsive cancellation within loops. Usetoken.WaitHandle.WaitOne(timeout)sparingly for synchronous waits. - Always dispose of
CancellationTokenSource.CancellationTokenSourceimplementsIDisposable. Failing to dispose of can lead to resource leaks, especially when using the internal wait handles.
What .NET engineers should know:
- 👼 Junior: Understand basic cancellation patterns using tokens and throwing exceptions when canceled.
- 🎓 Middle: Confidently implement cancellation in library methods and API endpoints, leveraging built-in support from framework methods.
- 👑 Senior: Design robust cancellation strategies, including token linking, proper resource cleanup (disposing), and guidance to teams on safe async cancellation patterns.
📚 Resources: Cancellation in Managed Threads
❓ Describe how IAsyncDisposable works and when you would implement it.
IAsyncDisposable is an interface in .NET introduced in C# 8.0 that allows objects holding unmanaged or asynchronous resources to be disposed asynchronously. It's useful when cleanup tasks involve asynchronous operations, such as network streams, database connections, or files, where synchronous disposal could cause performance issues.
Instead of the synchronous Dispose() method from IDisposable, IAsyncDisposable provides an asynchronous method: DisposeAsync().
Example implementation of IAsyncDisposable:
public class AsyncResourceHandler : IAsyncDisposable
{
private readonly Stream _stream;
public AsyncResourceHandler(Stream stream)
{
_stream = stream;
}
public async ValueTask DisposeAsync()
{
if (_stream != null)
{
await _stream.DisposeAsync();
}
}
}
// Usage example:
await using var handler = new AsyncResourceHandler(File.OpenRead("file.txt"));
// Perform async operations with handler
When should you implement IAsyncDisposable?
- When disposing resources involves I/O-bound asynchronous operations.
- When using classes like
DbContextin EF Core connections, file streams, or network connections that already support asynchronous disposal methods.
What .NET engineers should know:
- 👼 Junior: Understand that
IAsyncDisposableallows asynchronous resource cleanup to avoid blocking application threads. - 🎓 Middle: Identify scenarios where using
IAsyncDisposablecan improve application responsiveness and properly implement async disposal patterns. - 👑 Senior: Ensure that APIs communicate disposal patterns, correctly combine synchronous (
IDisposable) and asynchronous (IAsyncDisposable) disposal methods where applicable, and handle edge cases gracefully.
📚 Resources: Implement a DisposeAsync method
❓ How does an async iterator (IAsyncEnumerable<T>) differ from a synchronous iterator
IAsyncEnumerable<T> allows elements to be produced and consumed asynchronously, whereas a synchronous iterator (IEnumerable<T>) blocks the calling thread while producing elements. Async iterators are particularly useful for streaming data from slow or latency-prone sources, such as network APIs, databases, or file systems.
The main differences:
IEnumerable<T>: Blocking, single-threaded data retrieval.IAsyncEnumerable<T>: Non-blocking, supports asynchronous data retrieval.
Example async iterator usage:
public async IAsyncEnumerable<int> FetchNumbersAsync()
{
for (int i = 0; i < 5; i++)
{
await Task.Delay(1000); // simulate async delay
yield return i;
}
}
// consuming async iterator with await foreach
await foreach (var number in FetchNumbersAsync())
{
Console.WriteLine(number);
}What .NET engineers should know:
- 👼 Junior: Know that
IAsyncEnumerable<T>allows efficient handling of asynchronous data streams without blocking threads. - 🎓 Middle: Understand the mechanics of
await foreachIt's a natural back-pressure control that effectively leverages async iterators in data streaming scenarios. - 👑 Senior: Design and implement scalable APIs using async iterators, carefully managing cancellation tokens, error handling, and optimizing memory usage during asynchronous streaming.
📚 Resources: Tutorial: Generate and consume async streams using C# and .NET
Synchronization & Coordination Primitives
❓ What are the methods of thread synchronization?
Thread synchronization in C# involves coordinating the execution of multiple threads to ensure correct data access and program behavior. Various synchronization primitives are provided to manage thread interactions effectively.
Mutex
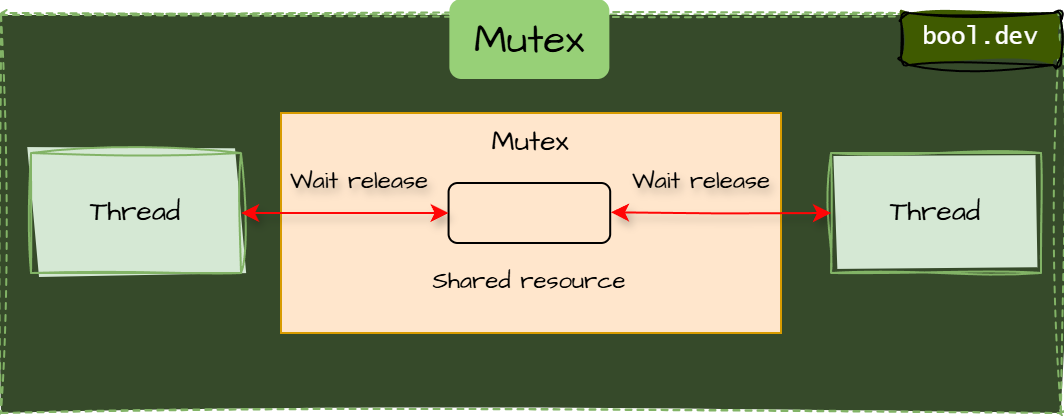
A Mutex (short for Mutual Exclusion) It is a synchronization primitive that ensures only one thread or process accesses a shared resource at a time. It's particularly suitable for scenarios involving cross-process synchronization. While you can create a named Mutex for inter-process communication, intraprocess synchronization usually doesn't require naming and is typically better handled using simpler primitives, such as the lock statement (Monitor), due to their lower overhead and complexity.
Example:
// Named mutex for inter-process coordination
using var mutex = new Mutex(false, "MyUniqueAppMutex");
bool hasHandle = false;
try
{
// Attempt to acquire Mutex immediately or wait for it (timeout)
hasHandle = mutex.WaitOne(TimeSpan.FromSeconds(5));
if (!hasHandle)
{
Console.WriteLine("Unable to acquire mutex. Another instance might be running.");
return;
}
// Critical section: safely perform actions that require exclusive access
Console.WriteLine("Mutex acquired, running critical section...");
}
finally
{
if (hasHandle)
mutex.ReleaseMutex(); // Explicitly release mutex
}
Semaphore
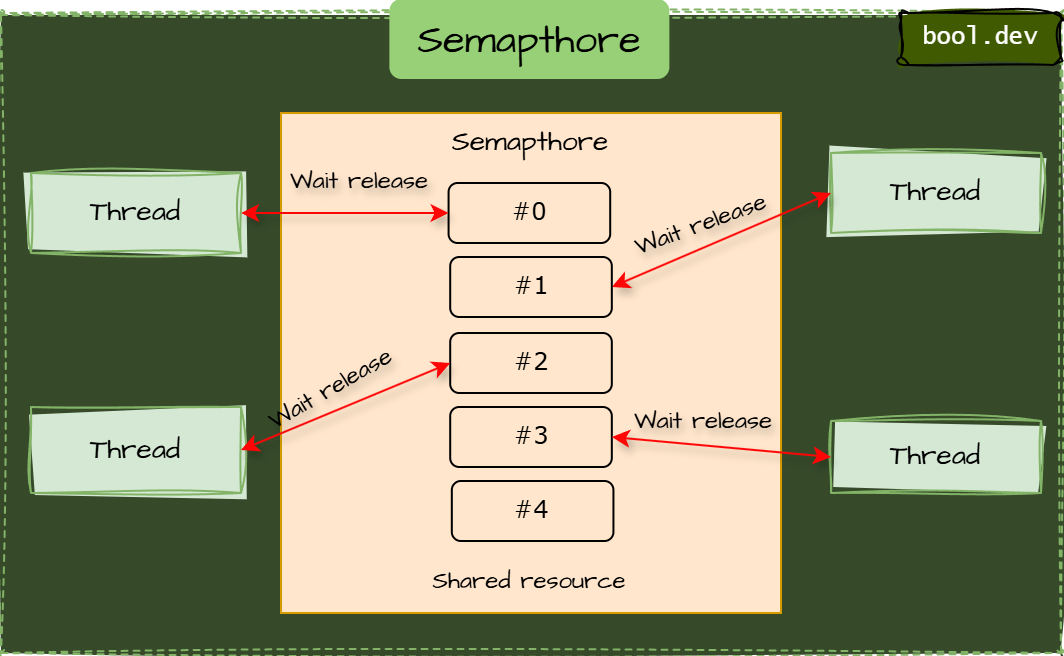
AutoResetEvent vs ManualResetEvent
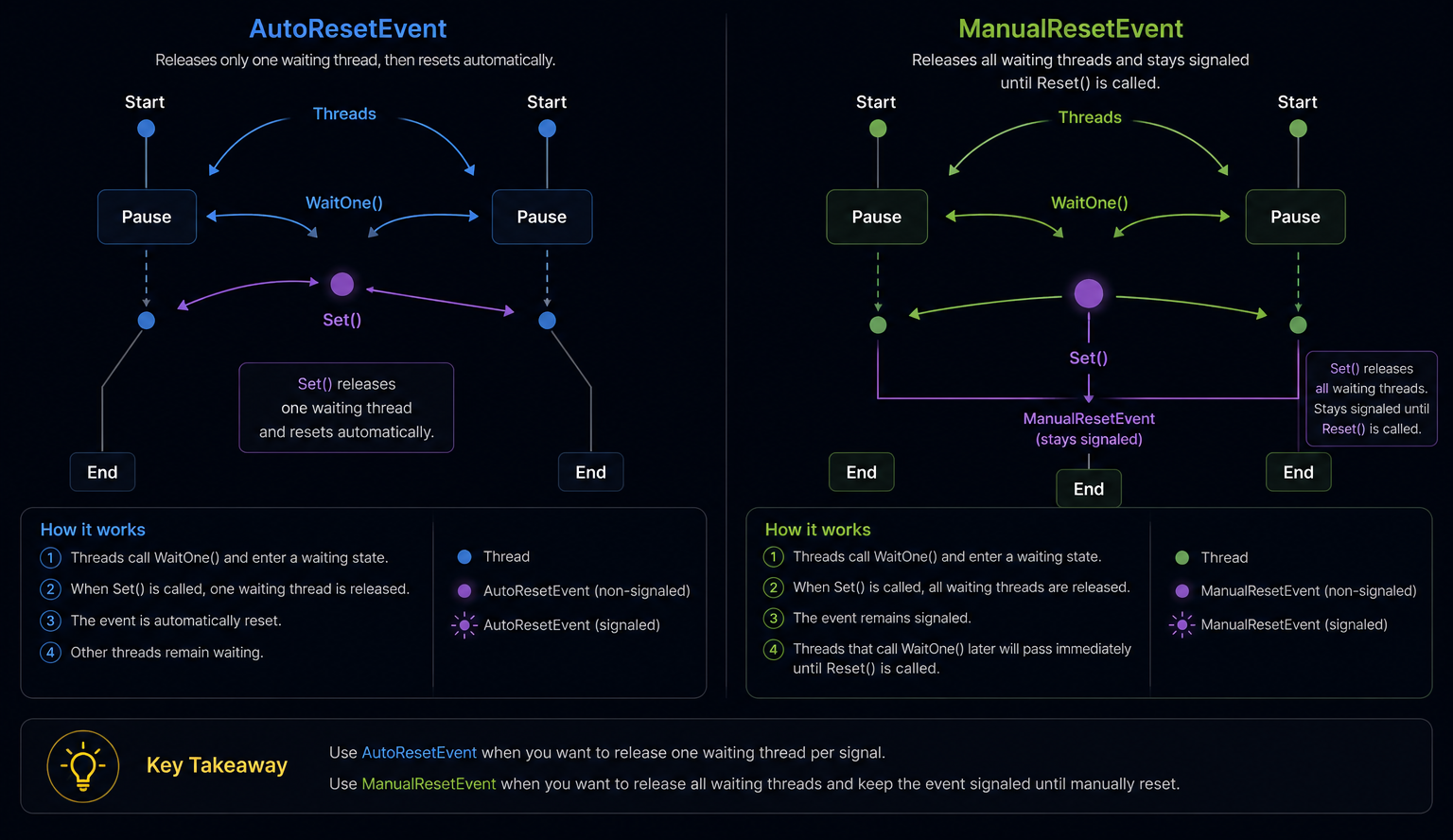
What .NET engineers should know:
- 👼 Junior: Recognize the need for synchronization to prevent race conditions and ensure data integrity in multithreaded applications. Familiar with simple synchronization mechanisms like the
lockstatement for mutual exclusion. - 🎓 Middle: Understand and implement synchronization constructs such as
Monitor,Mutex,Semaphore,AutoResetEvent, andManualResetEventto handle more complex threading scenarios. - 👑 Senior: Assess and select appropriate synchronization mechanisms based on specific use cases and performance considerations.
📚 Resources:
❓ How does the lock work? Can structures be used inside a lock expression?
The lock statement in C# ensures that a block of code runs exclusively by one thread at a time, preventing multiple threads from accessing shared resources simultaneously, which could lead to data corruption or unexpected behavior. It achieves this by acquiring a mutual-exclusion lock on a specified object, allowing only one thread to execute the locked code until the lock is released. The lock statement requires a reference type (e.g., an object) as its argument to ensure stable object identity, which is critical for maintaining mutual exclusion. Using a value type, such as a struct, is not allowed because structs are copied when boxed (an implicit conversion to object), creating a new object each time and breaking the guarantee of exclusive access, resulting in a compile-time error.
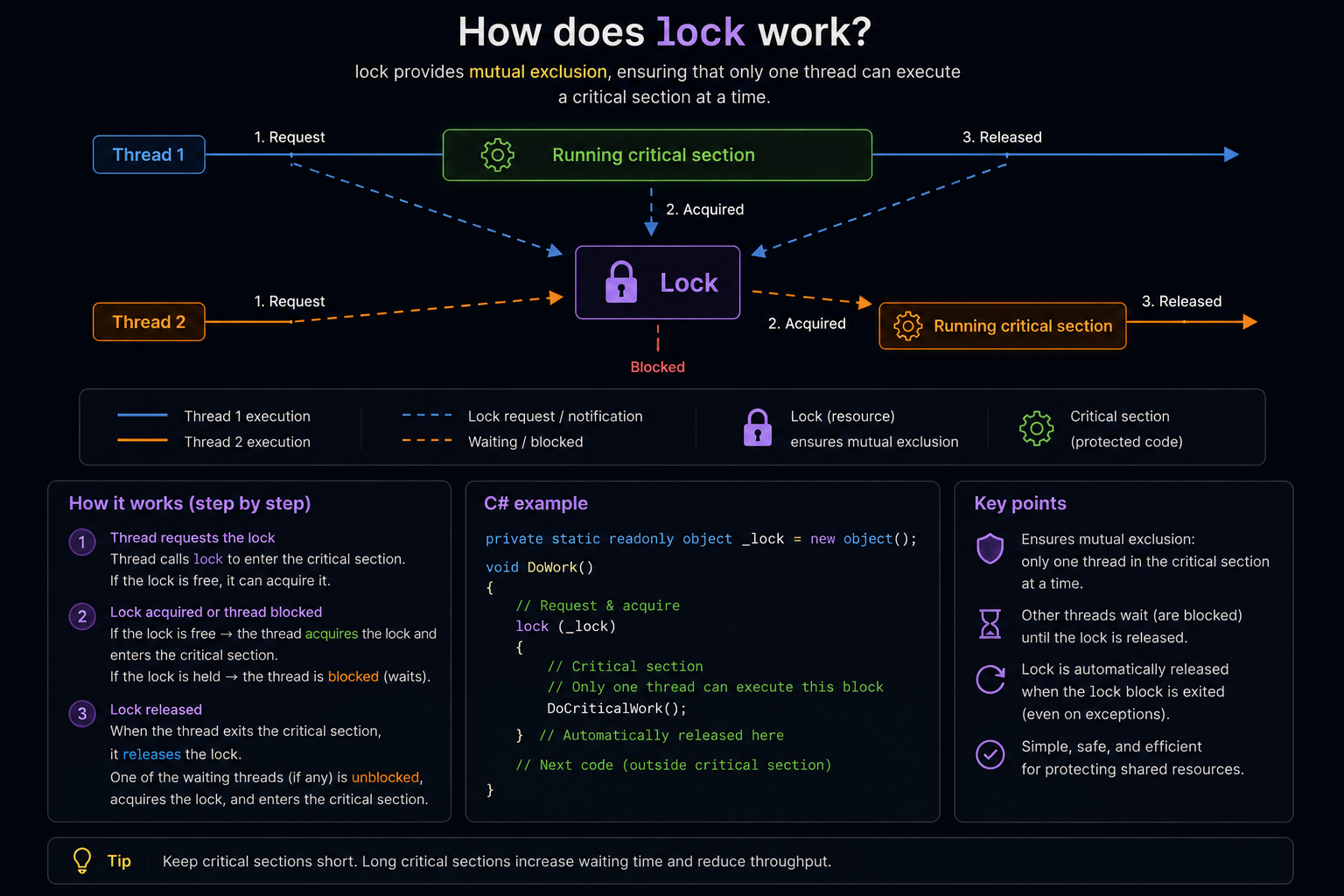
Example:
private readonly object _lockObject = new object();
lock (_lockObject)
{
// Thread-safe operations
}What .NET engineers should know:
- 👼 Junior: Should understand that the
lockstatement prevents multiple threads from running critical code sections simultaneously, ensuring thread safety, and it works only with objects, not structs. - 🎓 Middle: Expected to avoid locking on publicly accessible objects or types, as this can cause deadlocks or synchronization issues, and understand why structs can’t be used (due to boxing creating copies that undermine mutual exclusion).
- 👑 Senior: Should design systems to prevent deadlocks by enforcing consistent lock acquisition orders and minimizing nested locks. Fine-grained locking strategies, such as
ReaderWriterLockSlimfor read-heavy scenarios, should be implemented to reduce contention and optimize performance while ensuring stablelockreference types.
📚 Resources:
❓ What is a race condition, and how can you detect and prevent it?
A race condition occurs when two or more threads access shared data concurrently, and the outcome depends on the timing of their execution. This leads to unpredictable behavior, as the sequence of operations affects the program's correctness and reliability. Race conditions are common in multithreaded applications and can lead to bugs that are difficult to reproduce and debug.

Example of a race condition:
int counter = 0;
void Increment()
{
for (int i = 0; i < 1000; i++)
{
counter++;
}
}
If multiple threads execute the Increment method simultaneously without proper synchronization, the final value of the counter may be less than expected due to overlapping read and write operations.
To prevent race conditions, ensure that shared resources are accessed in a thread-safe manner. Common strategies include:
- Use synchronization primitives like
lockin C# to ensure that only one thread accesses a critical section at a time.
private readonly object _lock = new object();
void Increment()
{
lock (_lock)
{
counter++;
}
}
- Utilize atomic classes like
Interlockedfor simple operations.
Interlocked.Increment(ref counter);- Design data structures that remain unchanged after creation, thereby eliminating the need for synchronization.
- Store data so that each thread has its own copy, preventing shared access.
What .NET engineers should know:
- 👼 Junior: Understand that race conditions occur when multiple threads access shared data simultaneously without proper synchronization, resulting in unpredictable outcomes.
- 🎓 Middle: Be able to identify potential race conditions in code and apply synchronization techniques like locks or atomic operations to prevent them.
- 👑 Senior: Design systems with concurrency in mind, selecting appropriate synchronization mechanisms, and striking a balance between performance and thread safety.
📚 Resources:
- Race condition
- How to: Properly Simulate a Race Condition in C#
- Resolving Race Conditions and Critical Sections in C#
- Security and Race Conditions
- Race Conditions and Entity Framework Core
❓ What is the difference between Semaphore and SemaphoreSlim?
In C#, both Semaphore and SemaphoreSlim are synchronization primitives that control access to a resource by multiple threads, limiting concurrent access to a specified number of threads. However, they differ in design and use cases:
- Semaphore: A kernel-based synchronization primitive that supports cross-process synchronization, allowing multiple processes to coordinate access to shared resources. It supports named system semaphores, making it suitable for inter-process communication, but it incurs higher overhead due to kernel involvement.
- SemaphoreSlim: A lightweight, managed synchronization primitive optimized for intra-process synchronization within a single application. It does not support named semaphores and is designed for scenarios with short wait times, offering lower overhead than
Semaphore. In modern .NET,SemaphoreSlimis preferred for intra-process scenarios, especially in async-heavy applications, due to its efficiency and support for asynchronous operations likeWaitAsync.
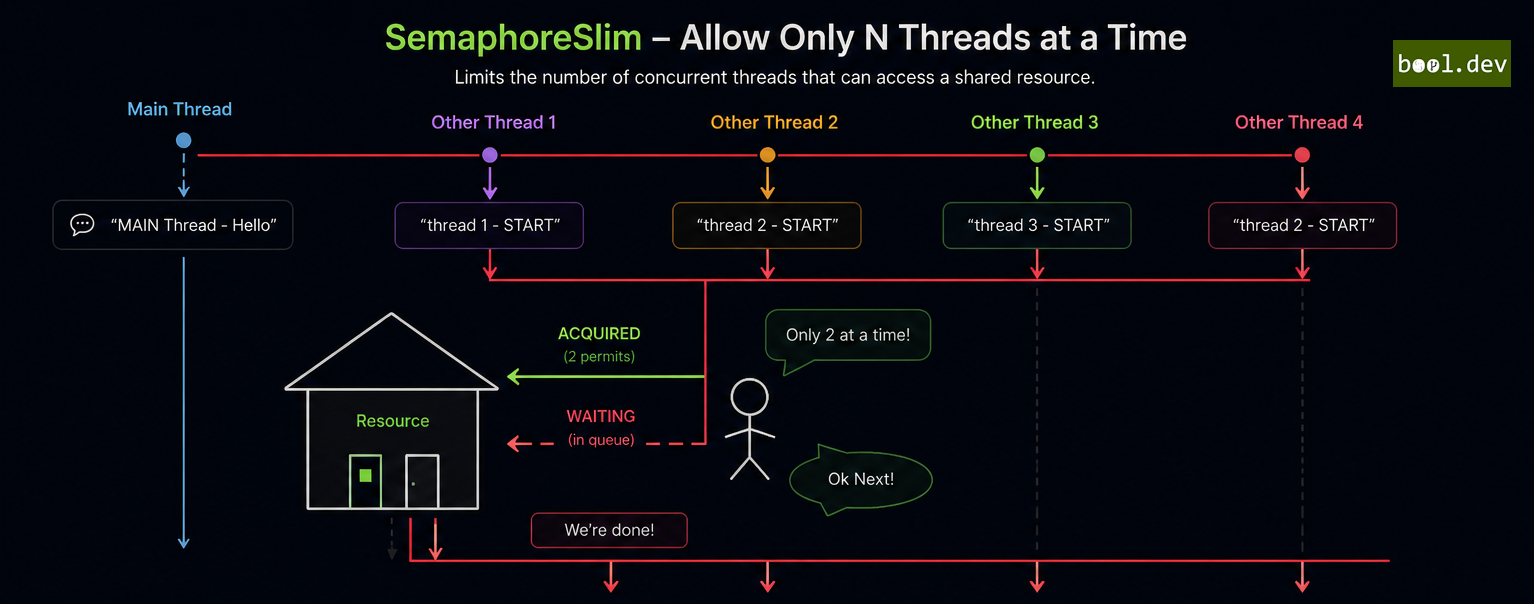
Example:
// SemaphoreSlim example for async scenarios
SemaphoreSlim semaphore = new SemaphoreSlim(initialCount: 3);
async Task AccessResourceAsync()
{
await semaphore.WaitAsync();
try
{
// Critical section
Console.WriteLine("Resource accessed");
await Task.Delay(1000); // Simulate work
}
finally
{
semaphore.Release();
}
}What .NET engineers should know:
- 👼 Junior: Should understand that SemaphoreSlim is used within a single application for thread coordination, Semaphore can work across multiple processes, and
SemaphoreSlimis common in modern .NET apps. - 🎓 Middle: Expected to recognize
SemaphoreSlim’s efficiency for intra-process synchronization due to its lower overhead and its support for asynchronous methods likeWaitAsync, making it ideal for async-heavy applications, compared to Semaphore’s kernel-based approach. - 👑 Senior: Should make informed choices between Semaphore and
SemaphoreSlimbased on requirements, prioritizingSemaphoreSlimfor intra-process, async-heavy scenarios to minimize overhead, usingSemaphoreonly for cross-process needs. Optimize synchronization strategies to consider performance, scalability, and integration with asynchronous code.
📚 Resources:
- Semaphore and SemaphoreSlim
- How to Use SemaphoreSlim in C#
- 📽️ Semaphores in C# (SemaphoreSlim and Semaphore)
❓ Compare ReaderWriterLockSlim with a simple lock (monitor) for protecting shared data.
Two standard options in .NET are the simple lock statement (which uses Monitor) and ReaderWriterLockSlim. Here's how they compare:
lock (Monitor)
The lock statement provides mutual exclusion, ensuring that only one thread can access the protected code section at a time, regardless of whether it's reading or writing. This approach is straightforward and efficient for scenarios with low contention or when write operations are as frequent as reads.
Pros:
- Simple to implement and understand.
- Low overhead in low-contention scenarios.
Cons:
- Readers and writers are treated the same; only one thread can access the resource at a time, which can lead to contention in read-heavy scenarios.
Example:
private readonly object _lock = new object();
private int _value;
public void Increment()
{
lock (_lock)
{
_value++;
}
}
public int GetValue()
{
lock (_lock)
{
return _value;
}
}ReaderWriterLockSlim
ReaderWriterLockSlim allows multiple threads to read concurrently while still ensuring exclusive access for write operations. This makes it suitable for scenarios with frequent reads and infrequent writes.
Pros:
- Allows multiple concurrent readers, improving performance in read-heavy scenarios.
- Provides upgradeable read locks, enabling a thread to read and later write safely.
Cons:
- More complex to implement correctly.
- Slightly higher overhead compared to
lockin write-heavy or low-contention scenarios. - Not suitable for asynchronous code (
async/await) as it doesn't support asynchronous locking.
Example:
private readonly ReaderWriterLockSlim _lock = new ReaderWriterLockSlim();
private int _value;
public void Increment()
{
_lock.EnterWriteLock();
try
{
_value++;
}
finally
{
_lock.ExitWriteLock();
}
}
public int GetValue()
{
_lock.EnterReadLock();
try
{
return _value;
}
finally
{
_lock.ExitReadLock();
}
}What .NET engineers should know:
- 👼 Junior: Understand that
lockis simple and effective for basic synchronization, but may cause contention when multiple threads frequently read shared data. - 🎓 Middle: Recognize scenarios where
ReaderWriterLockSlimcan improve performance by allowing concurrent reads, and learn to implement it correctly, managing read, write, and upgradeable locks. - 👑 Senior: Analyze application access patterns to determine the most suitable locking mechanism, taking into account factors such as read/write ratios and contention levels. Be aware of the limitations of each approach, such as
ReaderWriterLockSlimnot supporting asynchronous operations.
📚 Resources:
❓ When would you choose a ManualResetEventSlim over a SemaphoreSlim, and what are the memory/performance trade-offs?
ManualResetEventSlim wing multiple threads to be released simultaneously. It's optimized for short wait times, using spinning before resorting to kernel-based waits, which reduces context switches and improves performance in low-contention situations.
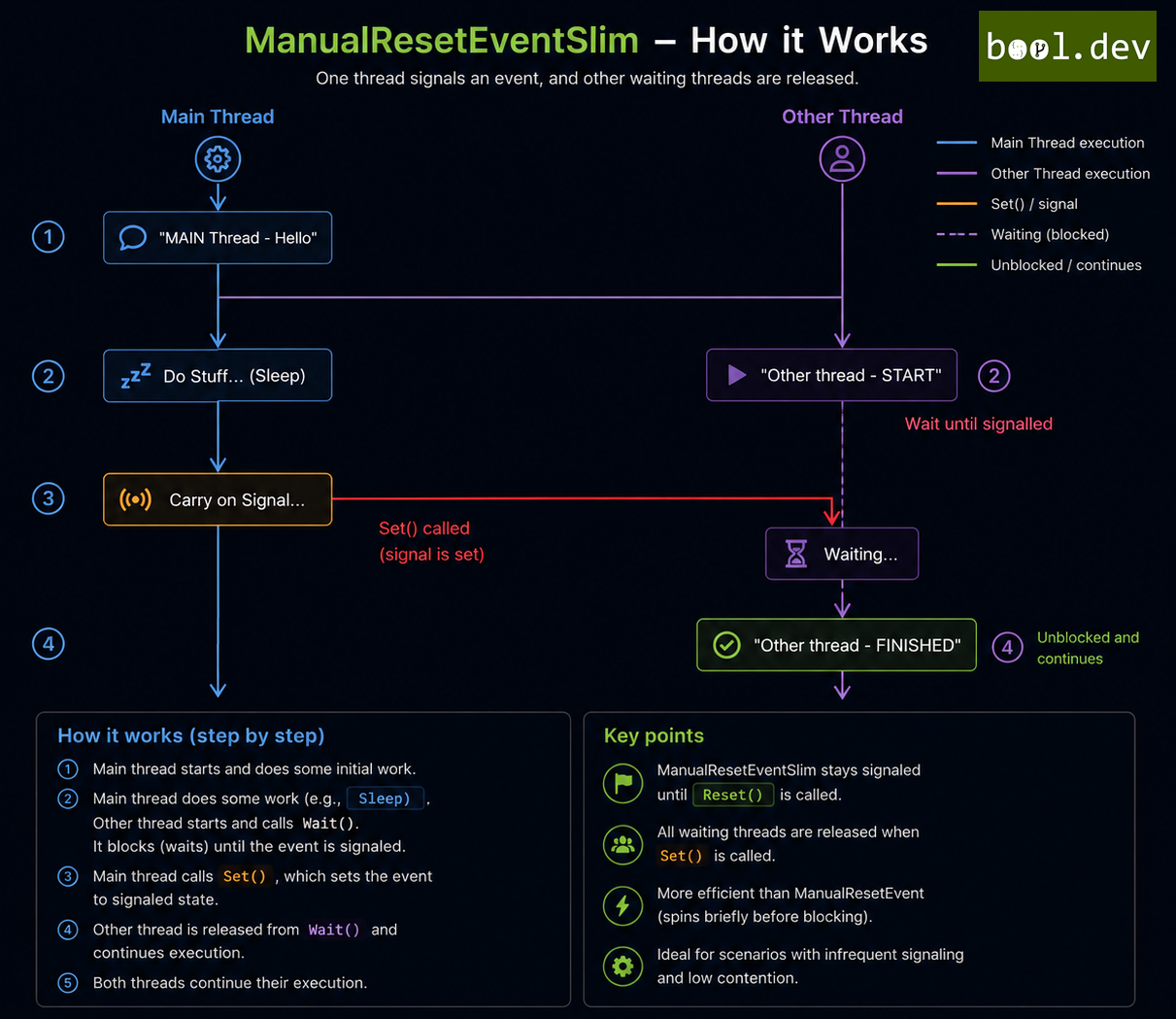
Pros:
- Faster for short waits due to spinning, minimizing context switch overhead.
- Lower memory overhead in low-contention scenarios.
Cons:
- Not suitable for long waits or high contention, as spinning can waste CPU cycles.
- Does not support asynchronous wait operations, which limits its use in asynchronous workflows.
SemaphoreSlim on the other hand, it controls access to a resource pool by maintaining a count of available slots. It's suitable when you need to limit the number of concurrent threads accessing a particular resource. Like ManualResetEventSlim, it employs spinning before falling back to kernel waits, but it supports asynchronous operations (e.g., WaitAsync), making it more versatile in modern asynchronous programming.
Pros:
- Supports asynchronous operations (
WaitAsync), making it suitable for async programming. - Efficiently manages a pool of resources with a specified concurrency level.
Cons:
- Slightly higher overhead compared to
ManualResetEventSlimin scenarios with very short waits. - More complex due to count management.
When to Use them:
Use ManualResetEventSlim when:
- You need to signal multiple threads to proceed simultaneously.
- Wait times are expected to be short, with spinning used to optimize performance.
- You're working within a single process and don't require asynchronous operations.
Use SemaphoreSlim when:
- You need to limit the number of concurrent threads accessing a resource.
- You're implementing asynchronous methods and need support for async/await via
WaitAsync. - Resource access needs to be throttled or controlled.
Performance Considerations:
ManualResetEventSlimexcels in short-wait scenarios due to its spinning mechanism, which avoids kernel waits. However, for long waits, spinning wastes CPU cycles; prefer async primitives like SemaphoreSlim's WaitAsync to avoid this.SemaphoreSlimis the better choice for async workflows, as it integrates seamlessly with async/await, reducing blocking and improving scalability.
What .NET engineers should know:
- 👼 Junior: Understand that
ManualResetEventSlimis used for signaling threads, whileSemaphoreSlimcontrols access to a limited resource pool. - 🎓 Middle: Recognize the performance implications of spinning versus kernel waits and choose the appropriate primitive based on wait times and contention levels.
- 👑 Senior: Design systems that leverage the strengths of each primitive, considering factors like asynchronous support, resource management, and system scalability.
📚 Resources:
- Threading in C#
- ManualResetEventSlim Class
- SemaphoreSlim Class
- .NET C# synchronization primitives cheatsheet for interview
❓ Explain how CountdownEvent and Barrier Coordinate multi-stage work and provide a use case for each.
CountdownEvent
CountdownEvent is designed to wait until a specified number of signals have been received. It's initialized with a count, and each call to Signal() decrements this count. Once the count reaches zero, any threads waiting on the event are released
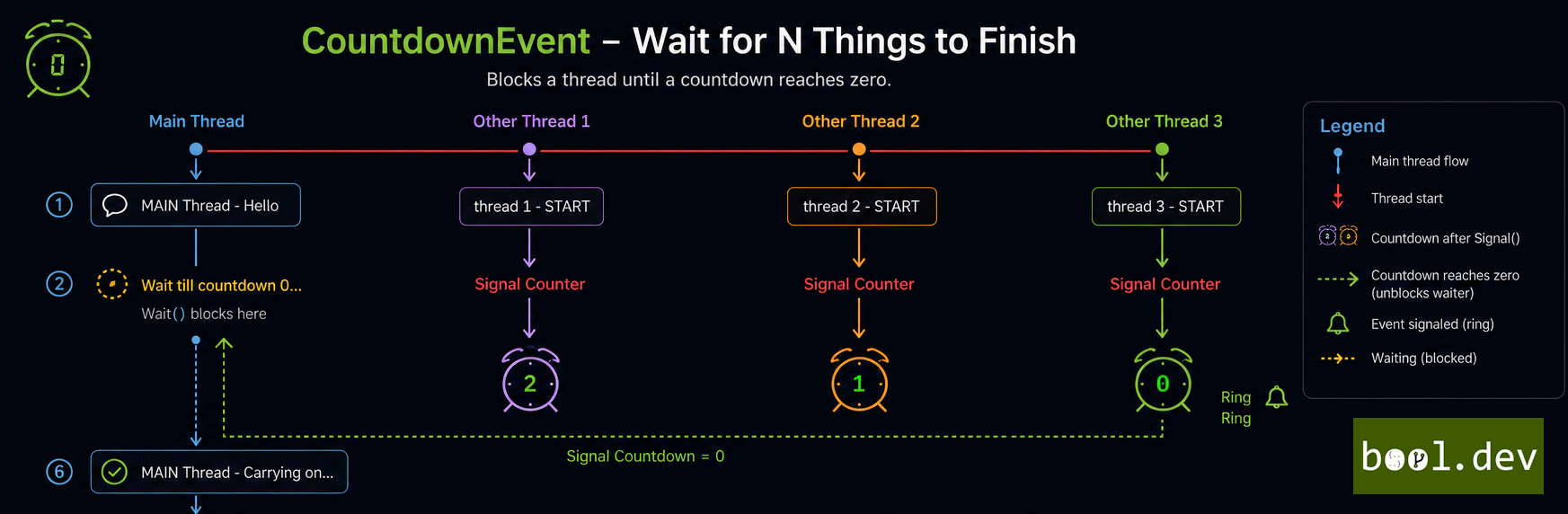
Use Case: Imagine you're launching multiple tasks in parallel and need to wait until all of them are complete before proceeding.
var countdown = new CountdownEvent(3);
void TaskWork()
{
// Perform task
countdown.Signal();
}
// Start 3 tasks
for (int i = 0; i < 3; i++)
{
Task.Run(TaskWork);
}
// Wait for all tasks to complete
countdown.Wait();In this example, the main thread waits until all three tasks have signaled completion.
Barrier
Barrier is used to synchronize multiple threads at a specific point, ensuring that all participating threads reach a particular stage before any proceed. It's beneficial for algorithms that proceed in phases.
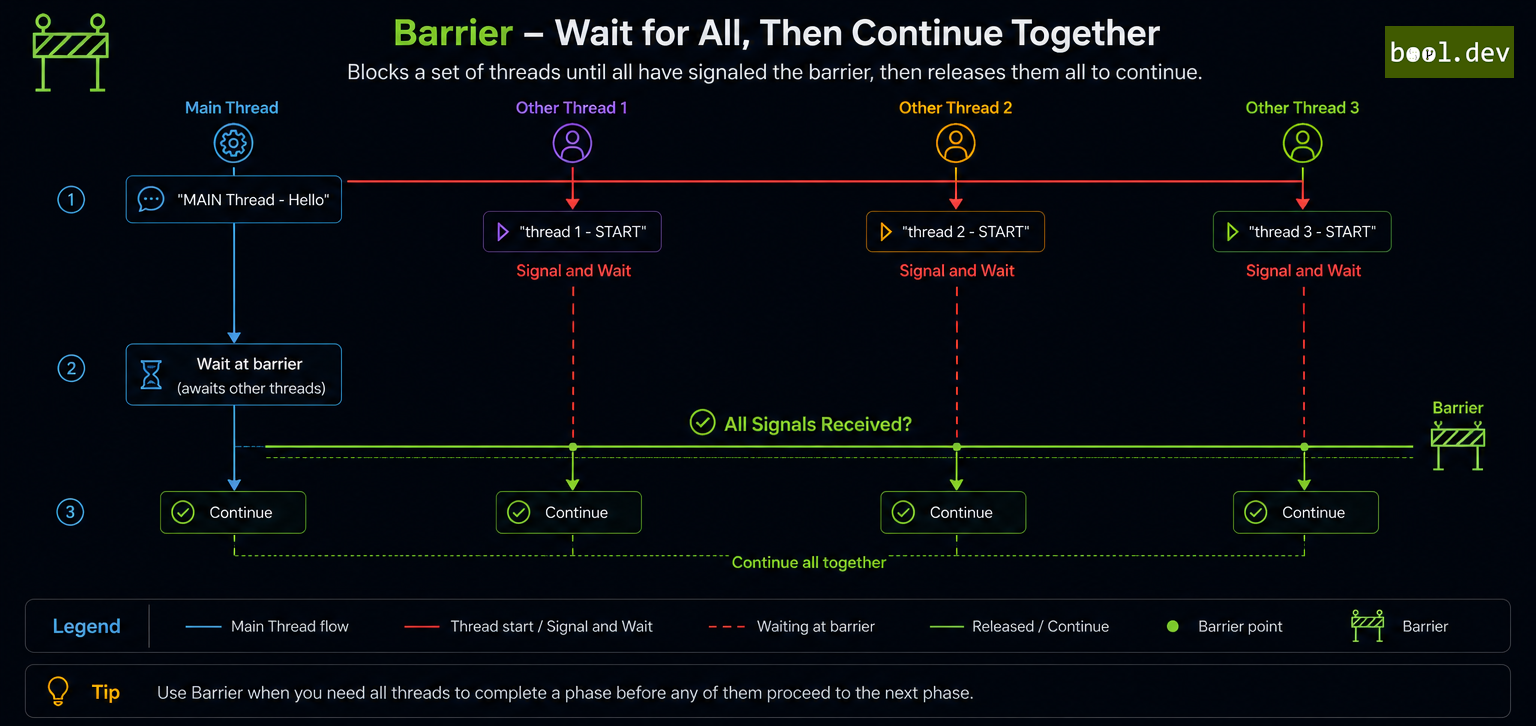
Use Case: Consider a simulation where multiple threads represent different entities, and each entity must complete a phase before moving to the next.
var barrier = new Barrier(3, (b) =>
{
Console.WriteLine($"Phase {b.CurrentPhaseNumber} completed.");
});
void SimulationWork()
{
for (int i = 0; i < 5; i++)
{
// Perform phase work
barrier.SignalAndWait();
}
}
// Start 3 simulation threads
for (int i = 0; i < 3; i++)
{
Task.Run(SimulationWork);
}
Here, all threads perform their phase work and then wait at the barrier. Once all have reached the barrier, they proceed to the next phase together.
Comparison
| Feature | CountdownEvent | Barrier |
|---|---|---|
| Purpose | Wait for a set number of signals | Synchronize threads at multiple phases |
| Reset Behavior | Manual reset required | Automatically resets after each phase |
| Post-Phase Action | Not supported | Supports a callback after each phase |
| Use Case | Waiting for multiple tasks to complete | Coordinating multi-phase operations |
What .NET engineers should know:
- 👼 Junior: Understand that
CountdownEventwaits for a fixed number of signals, whileBarriersynchronizes threads across multiple phases. - 🎓 Middle: Be able to implement both
CountdownEventandBarrierin appropriate scenarios, recognizing their reset behaviors and use cases. - 👑 Senior: Design complex multithreaded applications leveraging
Barrierfor phased operations andCountdownEventfor task completion synchronization, ensuring optimal performance and resource management.
📚 Resources:
❓ How do deadlocks manifest in asynchronous code, and what techniques help you avoid them?
In async C# code, deadlocks often arise when you mix synchronous blocking calls (like .Result or .Wait()) with await, particularly in contexts that demand continuity, such as UI threads (WPF/WinForms) or legacy ASP.NET. Typically, the calling thread blocks waiting for the task, while the task’s continuation tries to resume on that blocked thread, resulting in a classic “everyone waits indefinitely” deadlock
Deadlock scenario example:
// Runs on UI thread
var result = FetchDataAsync().Result; // blocks UI thread
async Task<string> FetchDataAsync()
{
var data = await httpClient.GetStringAsync(url); // awaits and captures UI context
return data; // tries to resume on UI thread
}Here, Result blocks the UI thread, but the await continuation needs that same UI thread—deadlock ensues.
Techniques to prevent deadlocks:
- Use
await. Avoid.Result,.Wait(),.GetAwaiter().GetResult()in async call chains. Always propagateasyncandawaitto top-level methods - Apply
ConfigureAwait(false)in library code. In code that does not update UI or rely on a context, use.ConfigureAwait(false)not to capture the synchronization context, allowing continuations on ThreadPool threads and avoiding deadlock.ConfigureAwait(false)is less critical in ASP.NET Core, but it is still suitable for reusable libraries. - Use
Task.Run(...)from UI/sync entry points. For calling async code from sync contexts, wrap it inTask.Runa run on the synchronization context. Combine.GetAwaiter().GetResult()to avoid needingConfigureAwait(false)inside. - When possible, design your stack so synchronous entry points call async methods only via
await, minimizing mixing sync and async.
What .NET engineers should know
- 👼 Junior: Know that blocking calls like
.Resultor.Wait()on async tasks can freeze or deadlock your UI or ASP.NET. - 🎓 Middle: Follow
asyncall the way and use.ConfigureAwait(false)in non-UI code to prevent synchronization context deadlocks. - 👑 Senior: Design libraries/apps with clear async boundaries, know when to use
ConfigureAwait, and apply patterns likeTask.Runwrappers when interacting with legacy sync code, gracefully preventing deadlocks.
📚 Resources:
- Avoid mistakes using Async/Await in C#
- Understanding Async, Avoiding Deadlocks in C#
- Understanding and Using ConfigureAwait in Asynchronous Programming
- Mixing Traditional Locks with Async Code in C#
- 📽️ 3 Ways To Avoid Deadlocks In C# Asynchronous Programming
Data Parallelism & Parallel LINQ
❓ How does Parallel.ForEachAsync improve over Parallel.ForEach, and what caveats exist for I/O-bound vs. CPU-bound loops?
Parallel.ForEachAsync is a newer addition that blends parallel looping with async support. It enables asynchronous operations within each iteration, while managing concurrency and resource use more intelligently than the traditional Parallel.ForEach.
Key Improvements:
- can
awaitinside the loop body (Func<T, CancellationToken, ValueTask>), which isn’t possible withParallel.ForEach. - By default, it limits the number of concurrent iterations to
Environment.ProcessorCount, and you can customize it viaParallelOptions.MaxDegreeOfParallelism
When to use each based on workload:
| Scenario | Use Parallel.ForEach | Use Parallel.ForEachAsync with await |
|---|---|---|
| CPU-bound | ✔️ Yes – takes full advantage of multiple cores | ⚠️ Possible, but simpler CPU work uses sync version |
| I/O-bound | ❌ Blocks threads during I/O | ✔️ Asynchronous I/O with controlled concurrency |
Suggestions & best practices
- Specify
MaxDegreeOfParallelism; otherwise, unlimited I/O calls could overwhelm external services. Parallel.ForEachavoids async overhead, whileParallel.ForEachAsyncmay add unnecessary complexity.Parallel.ForEachAsyncwill aggregate exceptions and cancel remaining iterations if any one fails.- Both use partitioning logic. Over-partitioning small collections can harm performance.
What .NET engineers should know:
- 👼 Junior: Understand that
Parallel.ForEachAsyncsupportsawaitinside loops and limits concurrency by default. - 🎓 Middle: Know how to configure
ParallelOptions(e.g.,MaxDegreeOfParallelism) for different workloads and choose between sync and async versions wisely. - 👑 Senior: Analyze workload patterns to pick the proper method, handle exceptions and cancellations gracefully, and ensure external systems aren’t overloaded by too much parallelism.
📚 Resources:
- Differences between Parallel.ForEach and await ForEachAsync
- Parallel.ForEachAsync in .NET 6
- Parallel.ForEachAsync and Exceptions
❓ Explain PLINQ (AsParallel) merge options and how they impact ordering and throughput.
PLINQ's merge options let you tune how results from parallel threads are combined before being consumed, striking a balance between responsiveness and overall throughput.
PLINQ supports three merge strategies via .WithMergeOptions(...):
NotBuffered: Streams each result immediately as it becomes available.AutoBuffered(default)Buffers results internally in batches and then yields them, balancing latency and throughput.FullyBufferedwaits for all threads to finish, buffers the entire result set, and then releases everything at once.
These options control when consumers see results relative to processing speed:
NotBufferedminimizes latency but may reduce throughput due to context-switch overhead.FullyBufferedmaximizes throughput but delays output until completion.AutoBufferedoffers a compromise between the two.
Ordering with AsOrdered() and merge options:
PLINQ processes elements in parallel, which can result in out-of-order processing by default. To preserve the original element order, you can call .AsOrdered():
var results = data.AsParallel()
.AsOrdered()
.WithMergeOptions(ParallelMergeOptions.NotBuffered)
.Select(...)
.ToList();Ordering incurs additional overhead, as PLINQ tracks indices to ensure the correct order.
It works with merge options: you can stream ordered results via NotBuffered, batch them with AutoBuffered, or wait for everything with FullyBuffered
ForAll vs. ForEach (foreach)
- Using
ForAll, PLINQ bypasses merging entirely—results are consumed directly by parallel threads. This maximizes throughput but doesn't guarantee ordering or buffering. - Using
foreach, PLINQ must merge results back to a single thread with the selected merge strategy and ordering behavior.
What .NET engineers should know
- 👼 Junior: Merge options control how quickly results appear (
NotBuffered) vs. how fast all results complete (FullyBuffered). - 🎓 Middle: Use
NotBufferedfor low-latency streaming,FullyBufferedfor batch processing, or accept the defaultAutoBufferedfor balanced scenarios. Add.AsOrdered()only if ordering matters. - 👑 Senior: Analyze your workload to choose the right merge strategy: low-latency dashboards benefit from
NotBuffered, heavy batch tasks thrive withFullyBuffered, andForAllbypasses ordering entirely for max performance. Always benchmark real-world use cases.
📚 Resources:
❓ What is a partitioner, and why is custom partitioning important for load balancing in parallel loops?
A partitioner in .NET TPL/PLINQ divides a data source into subsets (partitions) so that parallel loops or queries can process each segment concurrently. This division enables efficient distribution of work across multiple threads.
Custom Static Partitioner Example:
class MyPartitioner : Partitioner<int>
{
int[] source;
double rate;
public MyPartitioner(int[] source, double rate)
{ this.source = source; this.rate = rate; }
public override IList<IEnumerator<int>> GetPartitions(int count)
{
// Custom logic splits ranges based on rates
}
public override bool SupportsDynamicPartitions => false;
}When to Use Custom Partitioners
| Scenario | Default Behavior | Custom Partitioning Benefit |
|---|---|---|
| Uniform & Indexed | Balanced with range partitioning | Not needed |
| Variable timing on indexed data | Static splits cause idle threads | Tailored splits by processing cost |
| Non-indexed small workloads | Frequent chunk requests add sync overhead | Larger batches reduce overhead |
| Grouping requirement | Not supported | Custom partitioner groups items by key |
What .NET engineers should know
- 👼 Junior: A partitioner divides your data so that parallel loops run more efficiently. Default partitioners are effective for common patterns, but specialized workloads may experience issues.
- 🎓 Middle: Use
Partitioner.Create(...)withloadBalance:trueto improve throughput. Consider custom partitioners for balanced workloads or grouping needs. - 👑 Senior: Design custom partitioners tuned to the computation profile—balance chunks dynamically, avoid thread starvation, and minimize synchronization for optimal parallel performance.
📚 Resources:
- Custom Partitioners for PLINQ and TPL
- How to: Implement a Partitioner for Static Partitioning
- Optimizing Load Balancing in PLINQs
❓ Compare Parallel.Invoke with manually creating multiple Tasks joined by Task.WhenAll.
Both Parallel.Invoke and Task.WhenAll are used to run multiple operations concurrently in .NET, but they come from different paradigms and offer distinct benefits depending on your scenario.
Parallel.Invoke is part of the Task Parallel Library (TPL). It’s ideal for launching a set of synchronous, CPU-bound actions in parallel and waiting for all of them to complete:
- Designed for short-running, CPU-intensive tasks.
- Automatically uses the ThreadPool and tries to optimize thread usage.
- Executes synchronously—no async/await support.
- Easy and concise when you have multiple sync operations.
Example:
Parallel.Invoke(
() => ComputeA(),
() => ComputeB(),
() => ComputeC()
);Task.WhenAll with Task.Run or async methods. This approach uses asynchronous programming patterns and is better suited for I/O-bound, long-running, or asynchronous workloads.
Example:
await Task.WhenAll(
Task.Run(() => ComputeA()),
Task.Run(() => ComputeB()),
Task.Run(() => ComputeC())
);Or with async methods:
await Task.WhenAll(
DoSomethingAsync(),
DoSomethingElseAsync()
);Key Differences between Parallel.Invoke and Task.WhenAll
| Feature | Parallel.Invoke | Task.WhenAll |
|---|---|---|
| Ideal workload type | CPU-bound | I/O-bound, async operations |
| Async support | ❌ No | ✅ Yes |
| Return values | ❌ No | ✅ Yes (Task<T>) |
| Cancellation | With CancellationToken overload | Fully supported via token |
| Exception behavior | Aggregates and throws after all finish | Aggregates and throws via AggregateException |
| Use in UI apps / ASP.NET | ❌ Risk of blocking main thread | ✅ Non-blocking with async/await |
What .NET engineers should know
- 👼 Junior: Use
Parallel.Invokefor quick and simple concurrent CPU work; useTask.WhenAllfor async code. - 🎓 Middle: Understand how each tool maps to different concurrency models—
Parallel.Invokefor parallelism,Task.WhenAllfor asynchrony. - 👑 Senior: Decide based on workload characteristics—CPU or I/O-bound, synchronous or asynchronous—and design resilient code with cancellation, exception handling, and performance tuning in mind.
❓ What are the advantages and disadvantages of using value-type locals inside a highly parallel loop?
Using value-type locals (i.e., structs like int, double, Span<T>) inside highly parallel loops, such as those with Parallel.For, Parallel.ForEach, or PLINQ—can improve performance, but also comes with trade-offs. Whether they help or hurt depends on their usage pattern and mutability.
✅ Advantages:
1. Thread Safety by Design
Each thread gets its copy of value-type locals. No shared memory = no locking = no race conditions.
Parallel.For(0, 1000, i =>
{
int localCount = 0; // thread-local and isolated
localCount++;
});2. No Heap Allocation
Value types are stored on the stack, making them faster to allocate and garbage-collection-free (as long as they don’t get boxed).
3. Cache-Friendly
Small value types (like int, float) stay in CPU registers or L1 cache more easily, speeding up tight loops and computations.
4. Improved Performance for Simple Types
In computational tasks (such as matrix multiplication and vector math), using structs reduces overhead compared to heap-allocated reference types.
❌ Disadvantages
1. Copy Semantics Can Backfire
If a struct is large, passing it around by value can incur high copy costs. This especially hurts when used as loop-local state or passed to lambdas.
struct BigStruct { public int[] Data; } // bad idea in tight loops2. Boxing in Lambdas or PLINQ
Using value-type locals inside lambda captures may cause boxing, defeating the performance gain and even introducing hidden heap allocations.
int local = 42;
Parallel.For(0, 10, i => Console.WriteLine(local)); // fine
var boxed = local; // if captured improperly, may cause boxing
3. Immutability Constraints
Modifying struct fields (especially if they are nested) can be tricky due to C#’s value-copy-on-assignment behavior, which can lead to subtle bugs if not handled carefully.
4. Readability and Debugging Overhead
Working with stack-only types like Span<T> inside multi-threaded code can complicate debugging due to thread-local visibility and lifetime constraints.
🔍 Best Practices
- Use small, immutable value types (e.g.,
int,double) freely. - Avoid capturing large or mutable structs in closures.
- Prefer
ref struct(likeSpan<T>) only when you control the scope tightly and stay within the same thread. - Benchmark performance gains to assess significance—avoid premature optimization.
What .NET engineers should know
- 👼 Junior: Understand that value-type locals like
intorboolare safe to use in parallel code and prevent race conditions. - 🎓 Middle: Be aware of copying, boxing, and performance costs when using structs—especially large or mutable ones—in parallelized workloads.
- 👑 Senior: Design performant, thread-safe code by carefully choosing and structuring value-type usage. Avoid subtle bugs related to struct mutation, boxing in lambdas, and memory pressure in high-throughput loops.
📚 Resources: How to: Write a Simple Parallel.For Loop
Channels & Pipelines
❓ What is a Channel<T> in C#, and why should you use it?
Channel<T> is a high-performance, thread-safe messaging primitive for asynchronous producer-consumer scenarios. Think of it as a pipeline: one or more producers write messages into the channel, and one or more consumers read from it, without locks, queues, or blocking threads.
Unlike BlockingCollection<T>, channels are designed from the ground up for async/await and non-blocking concurrency.
It lives in System.Threading.Channels and is often used to:
- Decouple producers and consumers in high-throughput systems
- Build background workers or streaming pipelines
- Replace
ConcurrentQueue<T>+ polling hacks
Example
using System.Threading.Channels;
var channel = Channel.CreateUnbounded<string>();
// Writer (producer)
_ = Task.Run(async () =>
{
await channel.Writer.WriteAsync("message");
channel.Writer.Complete();
});
// Reader (consumer)
await foreach (var item in channel.Reader.ReadAllAsync())
{
Console.WriteLine(item); // message
}No locks, no polling, no Task.Delay loops. Just clean, async streaming.
❓ When to use Channel<T>
- You want async-compatible queues between producers and consumers
- You’re dealing with backpressure or wish to control throughput
- You’re building pipeline-style architectures or streaming data flows
It’s excellent for microservices, background jobs, logging pipelines, and event processing systems.
What .NET engineers should know about Channel<T>
- 👼 Junior: Should know it's a safe way to pass messages between threads or tasks.
- 🎓 Middle: Should understand how to create bounded vs unbounded channels, and how
ChannelWriter<T>andChannelReader<T>work. Should be comfortable withReadAllAsyncandWriteAsync. - 👑 Senior: Should know how to design flow-control with
Channel<T>, how to use multiple readers/writers, implement graceful shutdown, and manage backpressure. Should also benchmark againstBlockingCollection<T>,ConcurrentQueue<T>, and streaming alternatives likeIAsyncEnumerable.
📚 Resources:
❓ When would you choose Channel<T> over other concurrency constructs?
Channel<T> from System.Threading.Channels shines when you need asynchronous producer/consumer coordination with robust back-pressure control and high performance. Unlike traditional collections like BlockingCollection<T> or ConcurrentQueue<T>, it is built for async programming.
When to Choose Channels
| Scenario | Use Channel<T> When... |
|---|---|
| Async pipelines | You need producers and consumers to communicate asynchronously without blocking threads. |
| Back-pressure control | You want bounded buffering with options like dropping oldest or blocking until consumers catch up. |
| High-throughput workloads | You need performance comparable to lightweight queues (e.g., millions of messages/sec). |
| Clear API separation | You want distinct read/write API surfaces (ChannelReader, ChannelWriter). |
What .NET Engineers Should Know
- 👼 Junior: Channels are ideal for async producer/consumer tasks—they let you use
awaitinstead of blocking calls. - 🎓 Middle: Understand bounded vs. unbounded channels, choose proper back-pressure strategies, and ensure readers match producers.
- 👑Senior: Use channels in large-scale async pipelines—fine-tune single-reader/writer options, balance workloads, and ensure resource safety with clean shutdowns and proper cancellation handling.
📚 Resources:
- Processing data in parallel using Channels
- Performance Showdown of Producer/Consumer (Job Queues) Implementations in C# .NET
- An Introduction to System.Threading.Channels
- System.Threading.Channels library
❓ Compare System.Threading.Channels with BlockingCollection<T> for implementing producer-consumer patterns.
Use Channel<T> for modern, high-performance, async-aware producer-consumer patterns with flexible back-pressure and API clarity. Use BlockingCollection<T> only for simple, synchronous use-cases where await and non-blocking calls aren't required.
| Scenario | Prefer Channel<T> | Prefer BlockingCollection<T> |
|---|---|---|
| Async codebase | ✅ Support for await methods | ❌ Block-based only |
| High throughput | ✅ Outstanding performance | ❌ Higher overhead |
| Back-pressure needed | ✅ Built-in bounding/drop/wait strategies | ✅ Basic blocking |
| Simpler sync use-case | ❌ Overkill for small use-cases | ✅ Simple API, IEnumerable support |
| API design clarity | ✅ Separate Reader/Writer types | ❌ Single interface for both |
What .NET Engineers Should Know
- 👼 Junior: Know that Channels enable actual async producer-consumer patterns, while
BlockingCollection<T>is synchronous and blocks threads. - 🎓 Middle: Understand Channels offer higher performance, back-pressure control, and better API design; use them for modern async pipelines.
- 👑 Senior: Choose Channels for scalable, async-heavy systems; use bounded channels with appropriate policies and separate reader/writer roles. For light synchronous workloads or compatibility,
BlockingCollection<T>is still acceptable.
📚 Resources:
- Deep Dive into Channel Structure with .NET 9: Performance, Patterns, and New Developments
- Mastering .NET Channels: The Secret to High-Performance Background Processing
❓ How do bounded vs. unbounded channels control memory growth, and when should you choose one over the other?
Unbounded channels
- There is no fixed limit, and the buffer grows as fast as producers can push.
- No back-pressure: if consumers lag, memory usage can spike and even crash the app
- Suitable when producers and consumers are naturally balanced and memory isn’t a concern.
Bounded channels
- Have a set capacity, e.g.,
Channel.CreateBounded(10). - Provide back-pressure: writers either wait or drop items when the buffer is full, based on the configured
BoundedChannelFullModepolicy (e.g.,DropOldest,DropNewest, orWait). - Ideal when consumer speed may vary, memory must be controlled, or you want predictable behavior.
Example of Bounded Channel Configuration:
var channel = Channel.CreateBounded<string>(new BoundedChannelOptions(10)
{
FullMode = BoundedChannelFullMode.DropOldest
});When to choose each
| Use Case | Choose Unbounded | Choose Bounded |
|---|---|---|
| Well-balanced producer/consumer | ✅ Good option | ✅ Safe alternative |
| Risk of memory overload | ❌ Risky | ✅ Prevents OOM, handles overflow cleanly |
| Need back-pressure or slow producers | ❌ None | ✅ Offers wait, drop-oldest/newest policies |
What .NET engineers should know
- 👼 Junior: Unbounded channels can overflow your memory if producers are faster than consumers. Bounded channels help control memory usage and regulate producer speed.
- 🎓 Middle: Configure bounded channels with
BoundedChannelFullModeto choose between blocking and dropping behavior. Monitor system performance and memory to find the right capacity and policy. - 👑 Senior: Utilize bounded channels in mission-critical pipelines to prevent memory overflows and manage back-pressure effectively. Always specify
BoundedChannelFullModeto ensure predictable behavior under load.
📚 Resources
- Understanding Bounded and Unbounded Channels in .NET
- Deep Dive into Channel Structure with .NET 9: Performance, Patterns, and New Developments
❓ How do you gracefully shut down a channel-based pipeline without losing data?
To gracefully shut down a channel-based pipeline in .NET while ensuring no data is lost, follow these best practices:
1. Signal completion using Complete()
When all producers' work is done, call writer.Complete(). This signals to consumers that no more items will be written, allowing them to drain the channel to empty before finishing
Example:
await producerTask;
writer.Complete();
await consumerTask;
2. Consumer drains until the channel ends
Consumers should use ReadAllAsync(), or loop using WaitToReadAsync() and TryRead(). These patterns keep reading until the channel is empty and marked complete
await foreach (var item in reader.ReadAllAsync())
{
Process(item);
}3. Use cancellation tokens responsibly
Use CancellationToken to break out of blocking reads during shutdown while avoiding the abandonment of drained items. For example, wrap the loop in a try/finally block to drain remaining items after cancellation.
Example:
try
{
await foreach (var item in reader.ReadAllAsync(cancellationToken))
Process(item);
}
catch(OperationCanceledException) { /* shutdown signaled */ }4. Control shutdown order in hosted services
In apps with multiple background services, ensure the producer shuts down before the consumer. Register the producer first so it stops last, guaranteeing no messages remain unprocessed.
What .NET engineers should know
- 👼 Junior: Call
writer.Complete()so consumers know that no more data is coming and can finish processing safely. - 🎓 Middle: Use
ReadAllAsync()to drain the channel, handle cancellation tokens properly, and ensure no data is skipped. - 👑 Senior: In complex pipelines, coordinate shutdown across services—stop producers first, complete the channel, and only then stop consumers. Use a hosted service registration order to ensure the correct sequence, wrap consumers with exception handling, and log completion gracefully.
📚 Resources
- C# Channels — Efficient and secure communication between threads and tasks.
- Mastering .NET Channels: Building Efficient and Scalable Message-Passing Solutions
❓ What are System.IO.Pipelines in .NET, and when would you use them instead of streams or channels?
System.IO.Pipelines is a modern API designed for high-performance asynchronous streaming of binary data, particularly useful in scenarios involving low-level I/O operations, network protocol implementations, or real-time data processing. Pipelines provide efficient buffer management through reusable buffers (MemoryPool<byte>), minimal memory copying, built-in backpressure support, and seamless async read/write operations.
When to use System.IO.Pipelines:
- When building applications or middleware that process high-volume binary data, such as web servers (ASP.NET Core’s Kestrel internally uses pipelines), require real-time parsing, or utilize custom network protocols.
- Pipelines manage buffer allocation automatically using memory pooling (
MemoryPool<byte>), significantly reducing garbage collection overhead and memory fragmentation. - Pipelines reduce memory copying by allowing direct reading and writing to shared buffers, improving performance and efficiency compared to traditional
Streamoperations. - The pipeline API inherently handles backpressure, ensuring producers don't overwhelm consumers by automatically pausing and resuming the data flow based on consumption speed.
Comparing Pipelines, Streams, and Channels:
| Feature | System.IO.Pipelines | Stream | System.Threading.Channels |
|---|---|---|---|
| Data Type | Byte-oriented, low-level | Byte-oriented, general-purpose | Typed, high-level objects |
| Buffer Management | Efficient with memory pooling | Typically manual or less efficient | Not explicitly managed, type-safe buffering |
| Use Case | High-performance I/O, network protocols | General-purpose file/network I/O | Producer-consumer workflows with typed messages |
| Backpressure Control | Built-in | Manual (limited) | Built-in |
Example of using System.IO.Pipelines:
public async Task ProcessDataAsync(PipeReader reader, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
var result = await reader.ReadAsync(token);
var buffer = result.Buffer;
try
{
while (TryParseMessage(ref buffer, out var message))
{
HandleMessage(message);
}
if (result.IsCompleted)
break;
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
await reader.CompleteAsync();
}
bool TryParseMessage(ref ReadOnlySequence<byte> buffer, out Message message)
{
// Custom parsing logic here
message = default;
return false;
}What .NET engineers should know:
- 👼 Junior: Be aware that
System.IO.Pipelinesexist and offer efficient I/O handling with minimal memory overhead. - 🎓 Middle: Understand when pipelines offer significant performance advantages over traditional streams, particularly in I/O-heavy scenarios.
- 👑 Senior: Know how to design and implement custom high-performance streaming solutions using
System.IO.Pipelines, managing memory pools, buffer reuse, and optimizing backpressure handling. Clearly distinguish between scenarios suitable for pipelines, channels, and streams.
📚 Resources:
📖 Future reading
- Part 1: Core Language & Platform Fundamentals
- Part 2: Types and Type Features
- Part 3: Collections and Data Structures
- Part 5: Design Patterns
- Part 6: ASP.NET Core
- Part 7: SQL Database
- Part 8: NoSQL Databases
- Part 9: Microservices and Distributed Systems
- Part 10: Testing
- Part 11: Desktop Development
- Part 12: Mobile Development
- Part 13: AI
- Part 14: Agile & Scrum