Consistency Models for Distributed Systems


When you update something in a distributed system, such as changing your profile picture, the change doesn't reach every server immediately. Some may still display the old one for a while. That's the delay consistency models tackle: how data spreads, how up-to-date it seems to users, and the trade-offs we make for speed, availability, and accuracy. This ties into the CAP theorem, which says you can only pick two out of three: Consistency, Availability, or Partition Tolerance. Since networks often glitch, systems must choose between maintaining perfect accuracy and remaining always available.
Let's delve into the primary models and how they strike a balance between these choices.
Strong Consistency
Strong consistency is often the default expectation when you use a relational database locally. But when you distribute across regions or shards, you’ll pay for that guarantee. It’s safe, predictable, and great for financial systems, but slower because each write waits until all replicas agree.
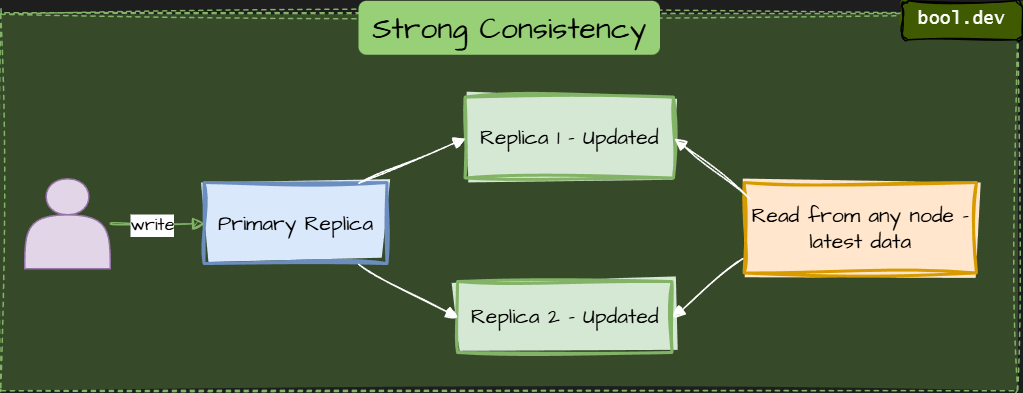
⚠️ Higher latency and lower availability
Examples:
- Traditional SQL systems on a single server (ACID relational DBs)
- Modern distributed SQL databases, such as YugabyteDB and TiDB, support global transactions and strong consistency.
- NoSQL systems in “strong” mode (e.g., Aerospike with strong consistency)
Bounded Staleness
Reads might lag writes, but only by a known amount. Offers a good balance for apps that require per-user state. Less overhead than global strong consistency, but still intuitive for the user.
Imagine a dashboard that shows inventory levels. It’s okay if you see updated values with a short delay of say 2 seconds or “5 versions back”, as long as you know the bounds.
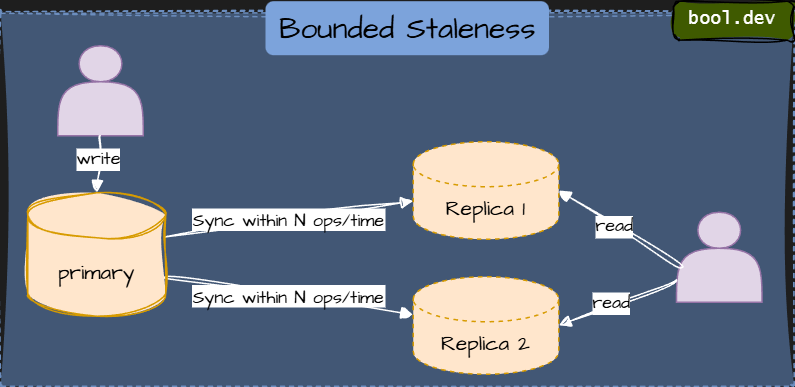
⚠️ Data may be slightly stale but within defined limits
Examples:
- Cosmos DB “Session” mode
- Systems that track session tokens or use sticky sessions
Session Consistency
In session consistency, within a single client session, reads are guaranteed to honor the read-your-writes and write-follows-reads guarantees. This guarantee applies to either a single “writer” session or sharing the session token for multiple writers.
Think of editing your own profile: you change it, refresh, and you see it. But someone else might still see the old version until it propagates.
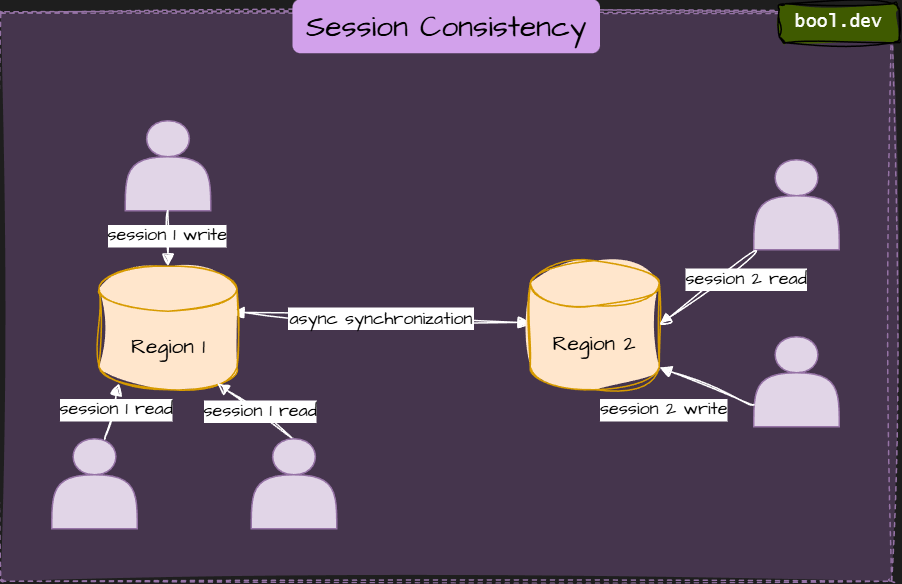
⚠️ Doesn’t enforce global real-time sync; replication logic gets more complex
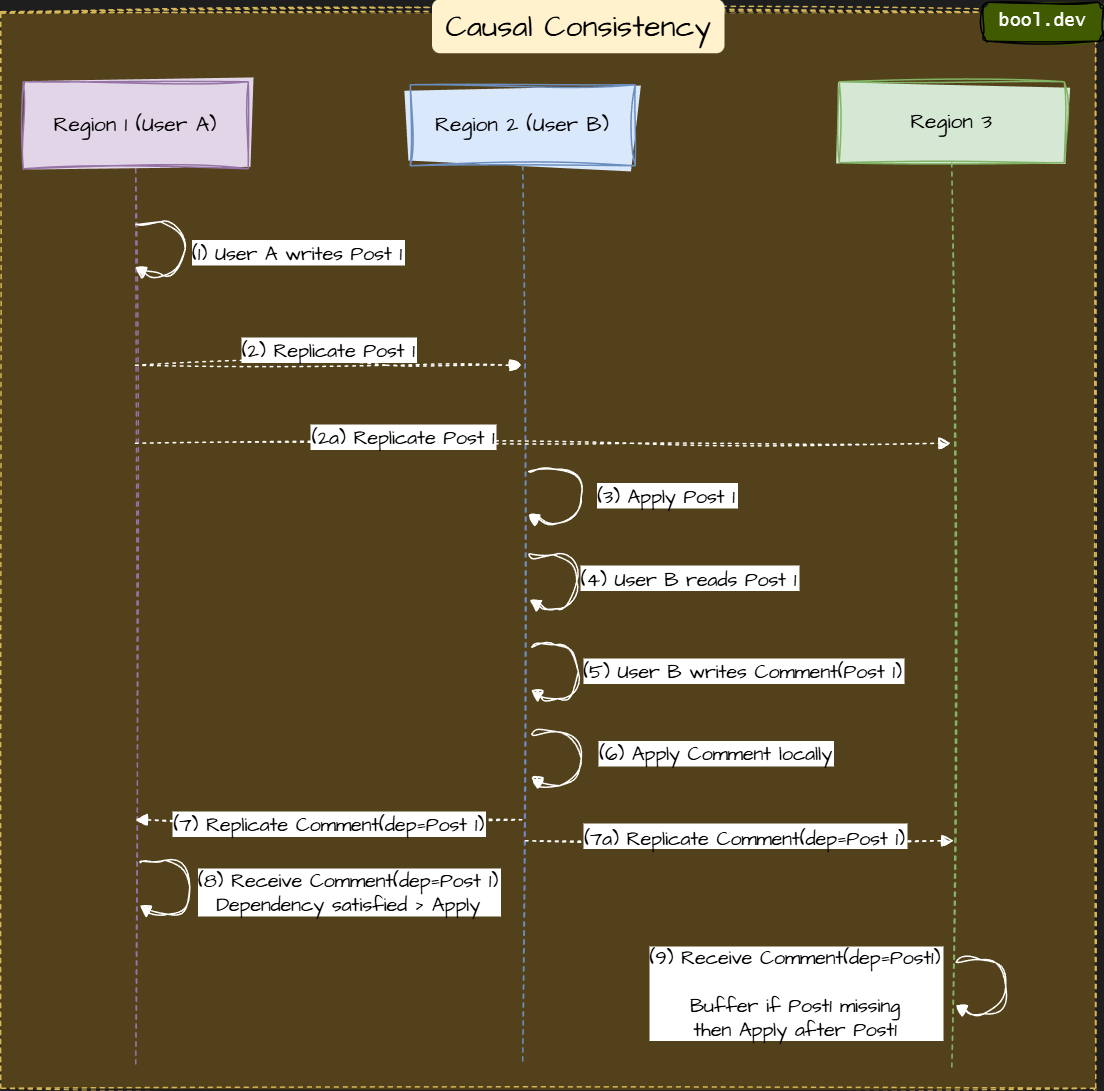
Causal Consistency
Operations that causally relate will be seen in order by everyone. If user experience or collaboration tools prioritise the order of actions, causal is often the sweet spot: you preserve meaningful sequences without incurring the full synchronous cost.
Example:
you ‘like’ a post, then you comment on it. You want everyone to see the like before the comment, even if both reach different replicas at different times. That is causal consistency.
⚠️ More complex replication logic
Flow:
| Step | Region | Event | Notes |
|---|---|---|---|
| 1–2 | R1 → R2,R3 | Post1 created and replicated | Base post |
| 3–6 | R2 | Reads and writes Comment(Post1) | Establishes dependency |
| 7 | R2 → R1,R3 | Replicates comment | Contains dependency metadata |
| 8 | R1 | Applies comment | Dependency satisfied instantly |
| 9 | R3 | Applies in causal order | Buffers until Post1 present |
Technical details
- Systems use vector clocks or Lamport timestamps to track dependencies.
- Causal consistency ensures that causally related operations are executed in a specific order, but allows concurrent/independent operations to be observed in different orders.
- It offers better availability and concurrency than complete strong consistency, but more guarantees than eventual consistency.
Use cases:
- Collaboration tools (shared docs, comments)
- Messaging/discussion systems where order matters
Eventual Consistency
Replicas will match… eventually. Different nodes may show different values momentarily, but convergence happens eventually.
Imagine posting a tweet: some people see it immediately, while others see it a second later. Over time, every server catches up, and everyone sees the same timeline.
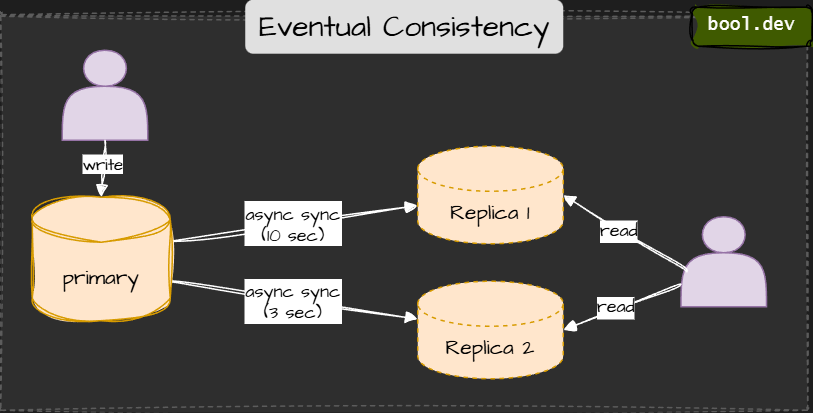
⚠️ Temporary inconsistency
Examples:
- Apache Cassandra
- Many caching or log-storage systems
- DynamoDB (in its default eventual mode)
Key takeaway: Choosing the Right Model
| Model | Data Freshness | Latency | Availability | Best For |
|---|---|---|---|---|
| Strong | Always up-to-date | High | Lower during partitions | Banking, ledgers, core record systems |
| Bounded Staleness | Slight lag, fixed bound | Medium | Medium | Shared dashboards, semi-real-time systems |
| Session | Your session sees your writes | Low | High | User profiles, chat apps |
| Causal | Cause-effect preserved | Medium | High | Collaboration tools, social feeds |
| Eventual | Eventually consistent | Very low | Very high | Caches, recommendations, logs |