ETL vs ELT

ETL (Extract, Transform, Load)

ETL stands for Extract, Transform, and Load. It is a common method to gather data from various sources, process it to meet specific requirements and load it into a target system, such as a data warehouse. ETL is beneficial in environments where data must be extensively cleaned and transformed to ensure quality and consistency before analysis, such as in traditional enterprise systems or when dealing with legacy data sources.
When to Use ETL:
- When dealing with large amounts of raw data in data lakes.
- Suitable for environments where cloud-based tools, such as Azure Data Factory or Google BigQuery, are available for processing.
ETL process
- Extract: Data is retrieved from databases, flat files, or APIs.
- Transform: Data is processed on an ETL server to meet specific requirements.
- Load: Transformed data is loaded into a data warehouse.
One common setup involves having a separate ETL server dedicated to processing data and loading it into a database serving as a data warehouse. This segregation ensures that heavy transformation queries do not burden the data warehouse:
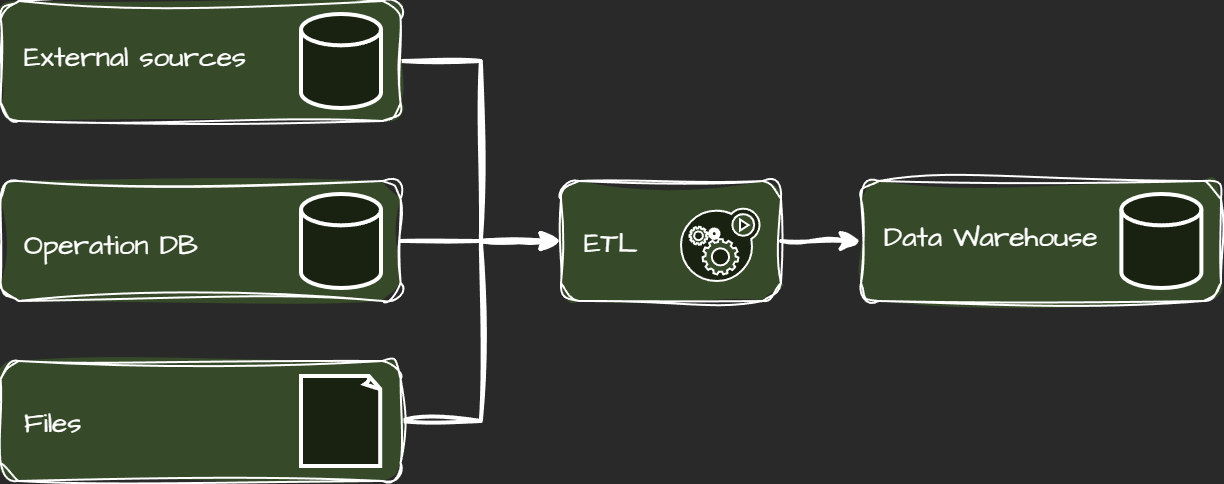
ETL process with staging
A common ETL architecture may involve a separate ETL server for processing and staging data before loading it into the database.
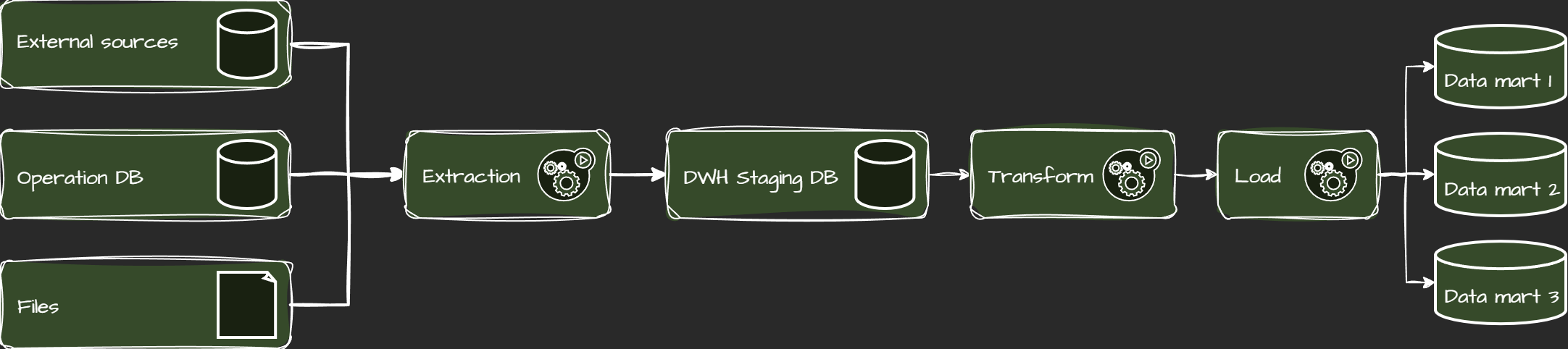
This allows for more efficient data processing and enables two variants:
- Staging Data: A temporary area where extracted data is stored before transformation.
- Hybrid Transformation: Initial transformation in ETL tools, followed by further processing in SQL queries for more efficiency or resource optimization.
ELT (Extract, Load, Transform)

ELT is similar to ETL, but you load the data before transforming it. You first extract the data and load it into a target system, often a data lake. Then, you transform it using the tools available in that system. ELT is usually used with big data systems that can handle heavy processing.
When to Use ELT:
- When you have a lot of raw data in a data lake.
- When you can use cloud tools to process the data.
ETL VS ELT: key differences
ETL and ELT differ in two primary ways. One difference is where the data is transformed, and the other is how data warehouses retain data.
| Feature | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| Definition | Extracts data, transforms it on a separate server, then loads it into the destination. | Extracts data, loads it directly into the destination, then transforms it there. |
| Process Order | Extract → Transform → Load | Extract → Load → Transform |
| Extract | Extracts raw data using APIs or connectors. | Extracts raw data using APIs or connectors. |
| Transform | Data is transformed on an intermediate server. | Data is transformed within the destination system (e.g., data warehouse). |
| Load | Transformed data is loaded into the destination. | Raw data is loaded directly into the destination. |
| Speed | Slower; transformation happens before loading. | Faster; loads data first and transforms in parallel. |
| Flexibility | Best for complex transformations and structured data. | Handles structured, semi-structured, and unstructured data efficiently. |
| Cost | Requires additional servers, increasing costs. | Fewer systems make it more cost-effective. |
| Maintenance | Secondary server adds to maintenance. | Simplified architecture reduces maintenance. |
| Requeries | Raw data is not retained, limiting flexibility. | Raw data remains available for future use. |
| Data Volume | Ideal for small, complex datasets. | Ideal for large datasets needing speed and scalability. |
| Data Lake Compatibility | Not compatible with data lakes. | Fully compatible with data lakes. |
| Privacy | Data can be pre-transformed to remove sensitive information. | Direct data loading requires stricter privacy measures. |
| Code Requirements | Relies on external processing for transformations. | Leverages in-database processing for faster execution. |
| Maturity | Well-established; trusted and documented. | Emerging; less mature and fewer best practices. |
ETL/ELT Tools
- Amazon Redshift – A cloud data warehouse solution designed for fast query performance on large datasets, enabling complex analytics at scale.
- AWS Glue – A serverless ETL service for cataloging, cleaning, enriching, and transforming data to make it queryable in other AWS services.
- Informatica – An enterprise-grade data integration tool that supports ETL, data governance, and AI-powered data management across multiple environments.
- ODI (Oracle Data Integrator) – A comprehensive data integration platform optimized for high-performance ETL operations and complex transformations.
- Qlik (Talend) – A tool offering robust ETL capabilities, data integration, big data handling, and cloud connectivity.
- DataStage – IBM’s ETL tool for high-volume data integration, supporting both on-premises and cloud environments.
- DBT (Data Build Tool) – A development environment for transforming raw data directly within data warehouses, emphasizing version control and collaboration.
- SSIS (SQL Server Integration Services) – A Microsoft tool for data integration, workflow applications, and ETL in SQL Server environments.
- Fivetran – A modern ELT tool offering automated data pipelines that synchronize data into cloud warehouses.
- Azure Synapse Analytics – An analytics service combining big data and data warehousing for ETL and ELT operations with advanced querying capabilities.
- Azure Databricks – A collaborative data engineering platform for ETL, machine learning, and big data analytics on Azure.
- Google Cloud Dataflow – A fully managed service for stream and batch data processing with support for ETL pipelines.
- Apache Spark – An open-source distributed computing system for large-scale ETL, machine learning, and real-time analytics.
- Airbyte – An open-source ELT platform enabling fast data integration and synchronization with various connectors.
- Power BI (Azure) – A Microsoft business intelligence tool for transforming and visualizing data through interactive dashboards.
- Apache Superset – An open-source data visualization tool that supports data exploration and lightweight ETL tasks.
- Snowflake – A cloud-based data warehouse platform offering scalable ELT capabilities and seamless data sharing.
- Hadoop – A framework for distributed storage and processing of large datasets, often used in big data ETL operations.
Summary

- ELT is faster, more scalable, and better suited for unstructured data, making it ideal for modern, high-volume use cases.
- ETL remains essential for privacy-sensitive workflows and legacy systems requiring structured data handling and pre-processing transformations.