How Modern LLMs Are Actually Trained: SFT, RLHF, DPO, Instruction Tuning, and Distillation


This guide explains how raw foundation models become production-ready AI assistants, coding copilots, and enterprise agents.
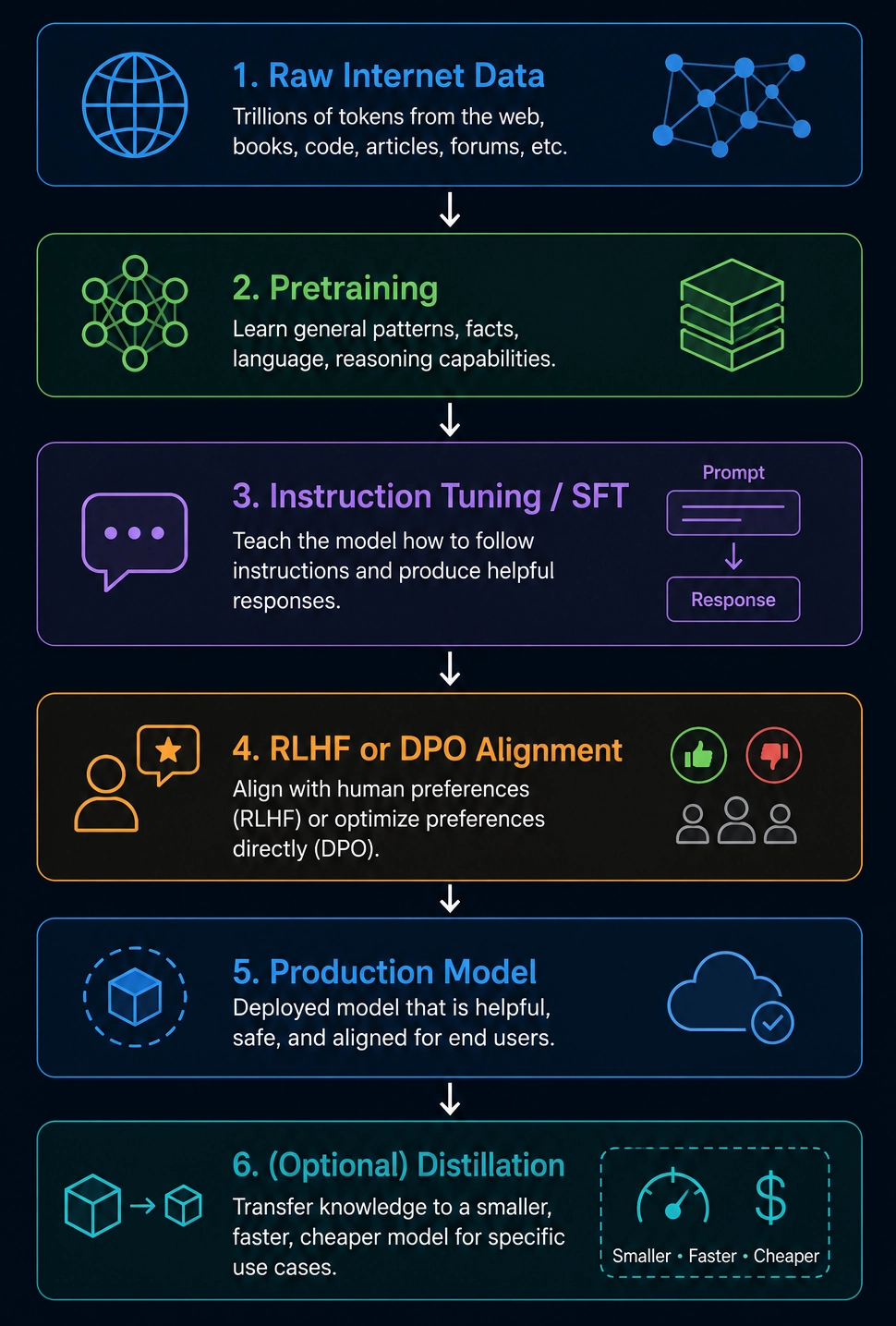
Modern LLMs need multiple training stages to become useful.
Model goes through:
- Pretraining
- Instruction tuning
- Supervised fine-tuning (SFT)
- Alignment training (RLHF or DPO)
- Optional distillation
Pretraining
The model first learns from massive datasets:
- Books
- Websites
- Code
- Forums
- Research papers
Example:
The sky is → blueThis step repeats billions of times. The model adjusts internal weights until predictions improve.
Pretraining produces the base model.
A raw base model has problems:
- Hard to control
- Poor at following instructions
- Verbose or chaotic output
- Unsafe for production
- Weak at structured outputs
Post-training stages fix these gaps.
What Is Instruction Tuning?
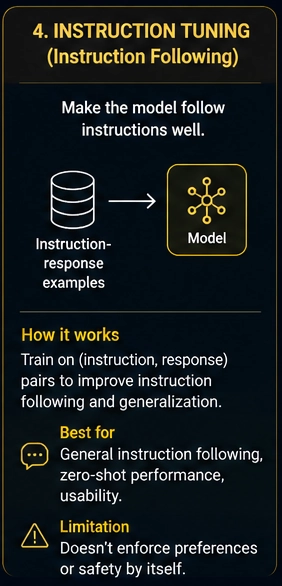
Instruction tuning teaches your model to follow human instructions.
Instead of predicting random internet text, you train on pairs:
Instruction → Expected ResponseExample:
Instruction:
Summarize this article in 3 bullet points.
Response:
Point 1
Point 2
Point 3Without instruction tuning, base models behave oddly:
User: Translate this to French.
Base model:
Translate this to French is a common NLP task...After instruction tuning:
Bonjour.Instruction tuning turns a raw language model into:
- Chat assistants
- Coding copilots
- Search assistants
- Enterprise AI agents
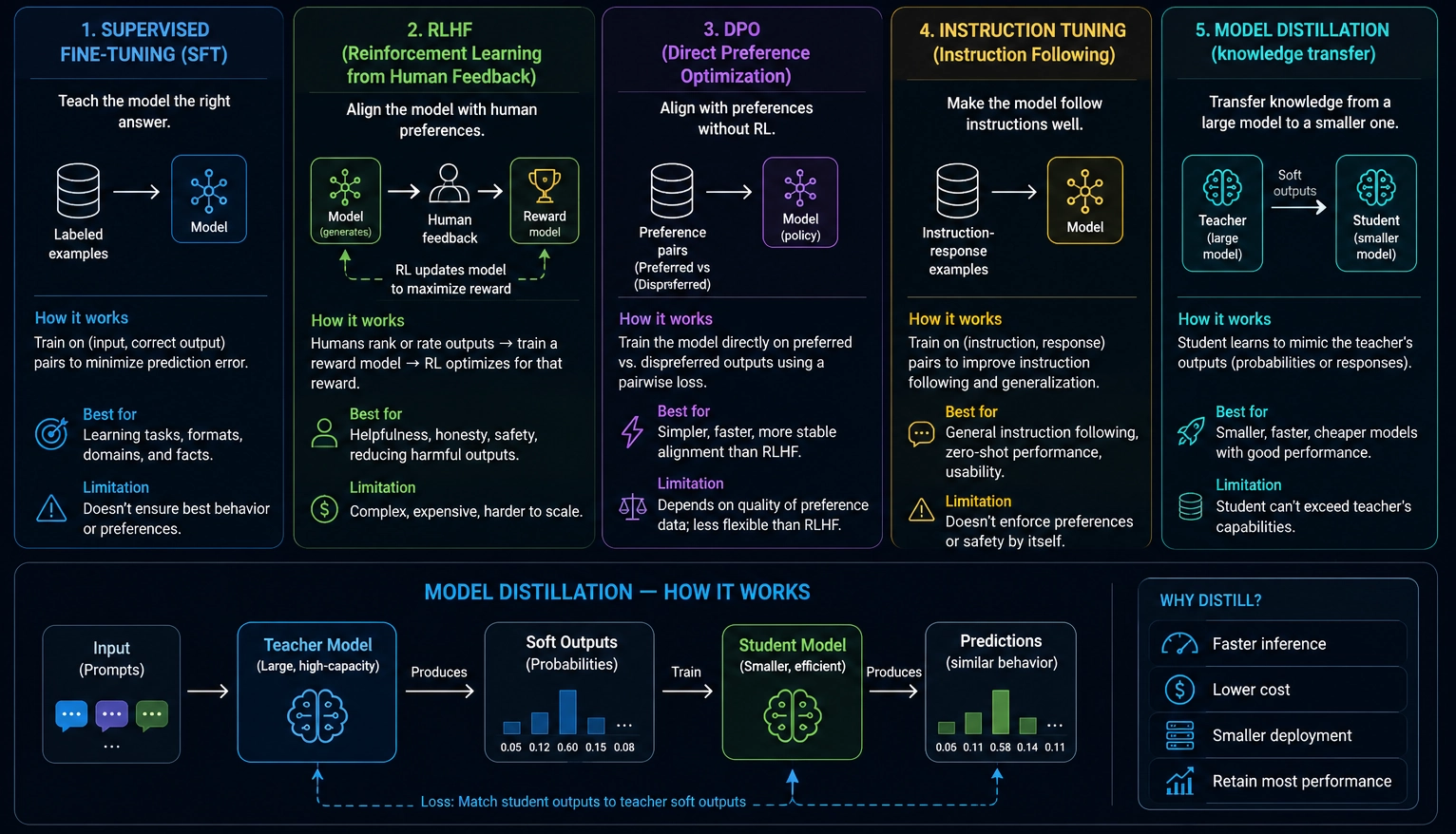
What Is Supervised Fine-Tuning (SFT)?
SFT trains your model on labeled examples.
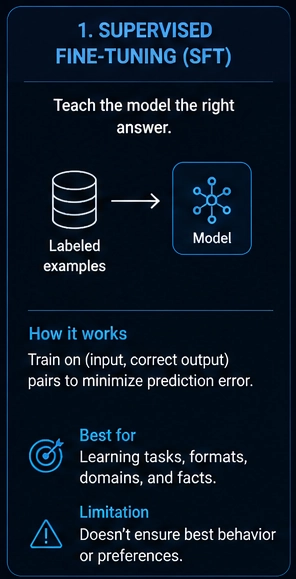
The model sees:
Input → Correct OutputThen learns to imitate the desired answer.
Example:
Question:
What is dependency injection?
Expected answer:
Dependency injection is a design pattern...The model adjusts weights to reduce prediction error.
SFT is one of the most important stages in practical LLM training.
Instruction Tuning vs SFT
Instruction tuning is a type of SFT focused on:
- Following instructions
- Conversational behavior
- Task completion
- Assistant-style interaction
SFT is broader. You apply SFT for:
- Legal analysis
- Medical classification
- Code generation
- SQL generation
- Internal company tasks
- JSON extraction
- Domain adaptation
Practical SFT Example
Suppose you build a support assistant for a bank.
You collect pairs:
Customer Question → Best Support ResponseExample:
Input:
My card was charged twice.
Output:
Please contact support using...Fine-tune your model on thousands of these examples. The model then responds consistently in your preferred style.
Limitations of SFT
SFT improves task performance. SFT alone fails to fully solve:
- Safety
- Preference alignment
- Toxic outputs
- Harmful content
- Ranking multiple valid responses
- Behavioral consistency
The model learns to imitate training examples. Real-world behavior gets messier.
RLHF and DPO fill these gaps.
What Is RLHF?
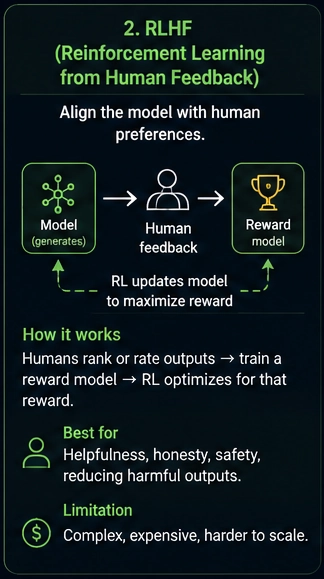
RLHF means Reinforcement Learning from Human Feedback.
RLHF aligns your model with human preferences.
The setup: humans rank multiple model outputs for the same prompt.
Example:
Prompt:
Explain Kubernetes.
Answer A:
Clear and accurate.
Answer B:
Confusing and incorrect.Humans pick the better answer. The system trains a reward model from these rankings. Reinforcement learning then optimizes the LLM toward outputs humans prefer.
Challenges with RLHF
- Human labeling cost
- Reinforcement learning complexity
- Training instability
- Reward hacking
- Difficult debugging
- Large infrastructure requirements
These pain points pushed many teams toward DPO.
What Is Direct Preference Optimization (DPO)?
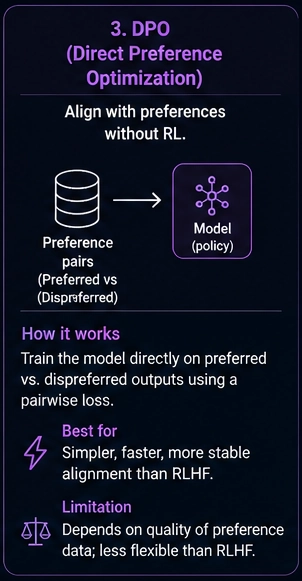
DPO solves a similar problem to RLHF, without the reinforcement learning stage.
Instead of:
Train reward model > Run RL optimizationDPO trains directly on preference pairs:
Preferred Answer > Rejected AnswerDPO is:
- Simpler
- More stable
- Easier to train
- Easier to reproduce
- Cheaper operationally
Most modern open-source alignment pipelines prefer DPO over classic RLHF.
Pros:
- Simpler pipeline
- Stable training
- No reinforcement learning stage
- Easier implementation
Cons:
- Less flexible for advanced optimization scenarios
- Heavy dependence on the preference dataset quality
What Is Model Distillation?
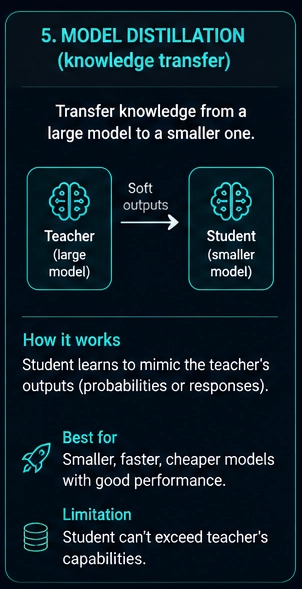
Distillation transfers knowledge from a large model into a smaller model.
The large model is the teacher. The smaller model is the student. The student learns to imitate the teacher.
Problems:
- Slow inference
- High GPU cost
- Large memory requirements
- High latency
- Expensive scaling
Distillation produces:
- Smaller models
- Faster inference
- Lower cost
- Easier deployment
- Better edge and mobile support
How Distillation Works
Standard training uses:
Input → Correct LabelDistillation uses teacher outputs instead:
Teacher probabilities:
Cat: 92%
Dog: 6%
Fox: 2%These probability distributions hold richer information than a single correct answer. The student learns behavior patterns from the teacher.
Cheat Sheet