Unique ID Generation Cheat Sheet


Unique identifiers are crucial for ensuring data integrity and uniqueness in applications. They help track, reference, and ensure consistency across various systems and services. This article contains a Cheat Sheet and descriptions of the different types of unique identifier generators, their methods, and tradeoff analysis to help you choose the best option for your application.
0. Database Auto-Increment

Example ID: 1, 2, 3 (incrementing sequentially)
Pros:
- Simple and ensures uniqueness within a single database
- Easy to implement in single-node applications
- Efficient for small-scale applications
- Sequentially ordered
- Efficient storage of a numeric value
Cons:
- Not suitable for distributed systems
- Scalability issues in distributed environments
- Performance can degrade with large datasets
- The limited range is based on the integer type (INT, BIGINT, etc.).
Database ID Implementation
CREATE TABLE Users (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL
);1. Twitter Snowflake

A 64-bit identifier that includes a timestamp, machine ID, and sequence number, ensuring uniqueness across distributed systems.
Example ID: 13572484591234567
Pros:
- Guaranteed unique within the distributed system
- Highly scalable, can generate millions of IDs per second
- Time-ordered, useful for chronological sorting
- Efficient storage as a 64-bit integer
Cons:
- Requires coordination between nodes to avoid collisions
- Complexity in managing and coordinating worker IDs
- Slightly slower than simple numeric increments due to bitwise operations
Twitter Snowflake Implementation
2. UUID V4 (Universally Unique Identifier)

A 128-bit identifier that is globally unique and can be generated independently by different systems without coordination.
Example ID: 550e8400-e29b-41d4-a716-446655440000
Pros:
- Globally unique without the need for a central authority
- Can be generated independently on multiple systems without coordination
- Fast generation, no need for network communication
Cons:
- Larger storage requirement (128-bit)
- No inherent orderability, random distribution
- Inefficient for use in databases with large datasets
UUID Generation
Mostly supported by default in different programming languages
Python
import uuid
# Generate a UUID
uuid_generated = uuid.uuid4()
print(uuid_generated)
Java
import java.util.UUID;
public class Main {
public static void main(String[] args) {
// Generate a UUID
UUID uuid = UUID.randomUUID();
System.out.println(uuid.toString());
}
}
Node.js
const { v4: uuidv4 } = require('uuid');
// Generate a UUID
const uuid = uuidv4();
console.log(uuid);
JavaScript
function uuidv4() {
return "10000000-1000-4000-8000-100000000000".replace(/[018]/g, c =>
(+c ^ crypto.getRandomValues(new Uint8Array(1))[0] & 15 >> +c / 4).toString(16)
);
}
console.log(uuidv4());C#
using System;
class Program
{
static void Main()
{
// Generate a UUID
Guid uuid = Guid.NewGuid();
Console.WriteLine(uuid.ToString());
}
}
PHP
function GUID()
{
if (function_exists('com_create_guid') === true)
{
return trim(com_create_guid(), '{}');
}
return sprintf('%04X%04X-%04X-%04X-%04X-%04X%04X%04X', mt_rand(0, 65535), mt_rand(0, 65535), mt_rand(0, 65535), mt_rand(16384, 20479), mt_rand(32768, 49151), mt_rand(0, 65535), mt_rand(0, 65535), mt_rand(0, 65535));
}Ruby
require 'securerandom'
# Generate a UUID
uuid = SecureRandom.uuid
puts uuid
Go
package main
import (
"fmt"
"github.com/google/uuid"
)
func main() {
// Generate a UUID
uuid := uuid.New()
fmt.Println(uuid.String())
}
Bash
#!/bin/bash
# Generate a UUID
uuid=$(uuidgen)
echo $uuid
3. UUID v7
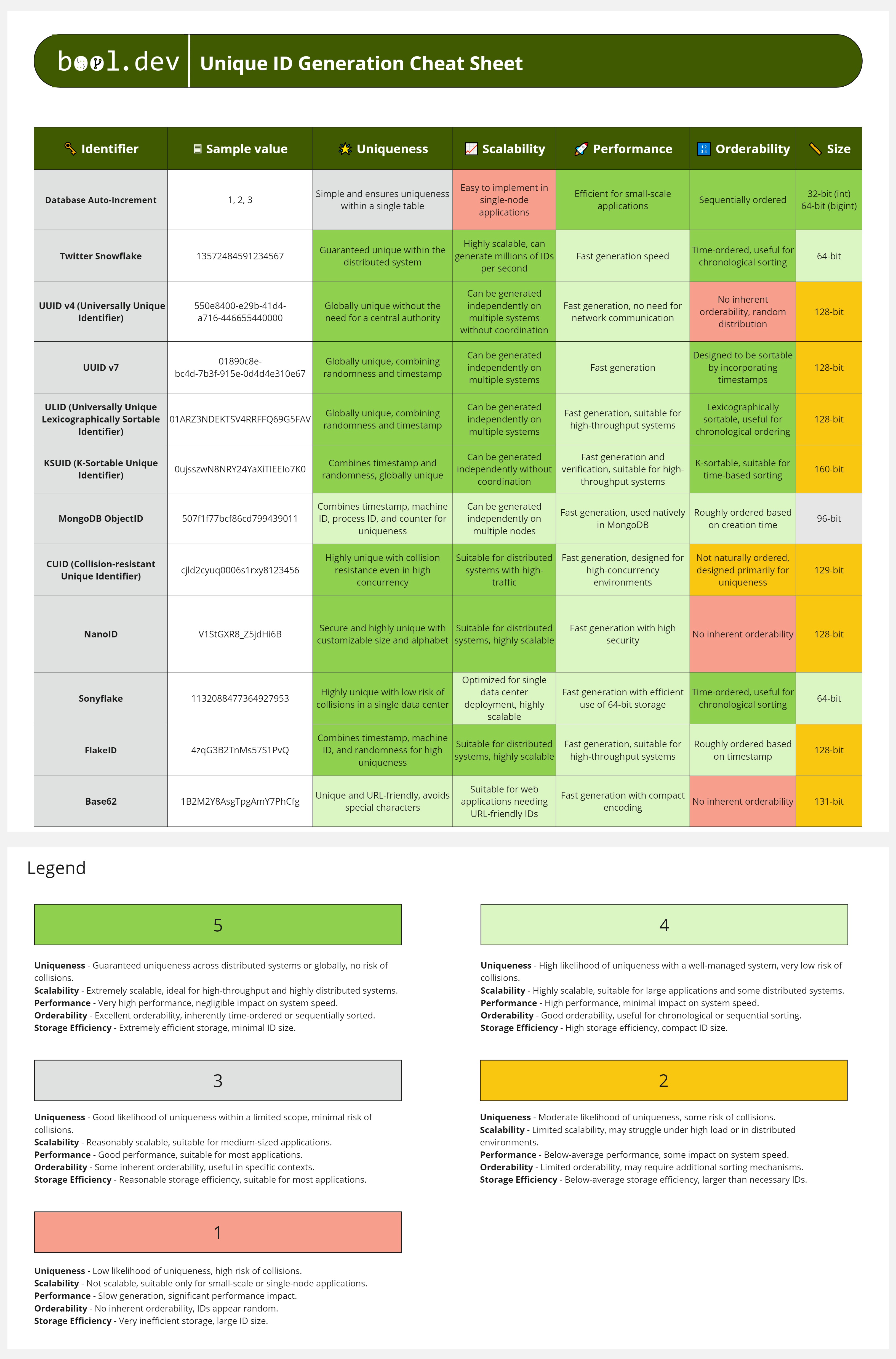
UUIDv7 is a new variant of UUID that incorporates a timestamp for sortable and unique identifiers, combining elements of UUID and ULID.
Example ID: 01890c8e-bc4d-7b3f-915e-0d4d4e310e67
Pros:
- Combines global uniqueness with timestamp-based sorting.
- Can be generated independently on multiple systems.
- Maintains compatibility with existing UUID systems and libraries.
- Useful for chronological sorting and time-based queries.
Cons:
- Larger storage requirement (128-bit).
- Slightly more complex generation algorithm than traditional UUID.
- Performance impact due to timestamp extraction.
4. ULID (Universally Unique Lexicographically Sortable Identifier)
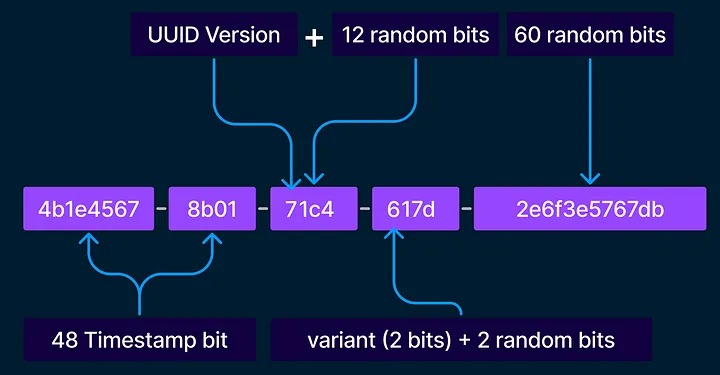
A 128-bit, lexicographically sortable identifier combines timestamps and randomness to ensure uniqueness and orderability.
Example ID: 01ARZ3NDEKTSV4RRFFQ69G5FAV
Pros:
- Globally unique, combining randomness and timestamp
- Can be generated independently on multiple systems
- Is compatible with UUID/GUID's
- 1.21e+24 unique ULIDs per millisecond (1,208,925,819,614,629,174,706,176 to be exact)
- Lexicographically sortable
- Uses Crockford's base32 for better efficiency and readability (5 bits per character)
- Case insensitive
- No special characters (URL safe)
- Monotonic sort order (correctly detects and handles the same millisecond)
Cons:
- A slightly more complex generation algorithm
- Larger than Snowflake and others
ULID Implementation
5. KSUID (K-Sortable Unique Identifier)

A 160-bit identifier that is also sortable by time and includes a timestamp, random payload, and checksum.
Example ID: 0ujsszwN8NRY24YaXiTIEEIo7K0
Pros:
- Combines timestamp and randomness, globally unique
- Can be generated independently without coordination
- Fast generation and verification, suitable for high-throughput systems
- K-sortable, suitable for time-based sorting
- Structured format aids in unique and ordered ID generation
Cons:
- Larger storage requirement (160-bit)
- Complexity in generation algorithm
- Additional overhead due to checksum verification
KSUID Implementation
6. MongoDB Object ID
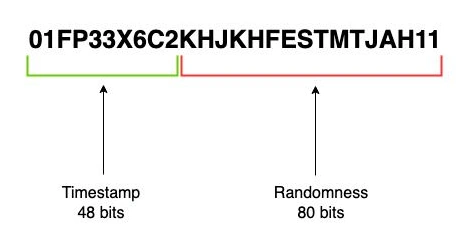
A 96-bit identifier that includes a timestamp, machine ID, process ID, and a counter, ensuring uniqueness and a rough creation order.
Example ID: 507f1f77bcf86cd799439011
Pros:
- Combines timestamp, machine ID, process ID, and counter for uniqueness
- Can be generated independently on multiple nodes
- Fast generation, used natively in MongoDB
- Roughly ordered based on creation time
- 96-bit size balances uniqueness and storage efficiency
Cons:
- Not guaranteed to be globally unique in all scenarios
- Potential for collision if machine and process IDs are not managed correctly
- Less efficient than simple integer-based IDs
- Unique to MongoDB: ObjectId is only compatible with MongoDB and might not work with other database systems. The ObjectId format may need to be converted or mapped if you need to integrate with a different database or move to a new one.
7. CUID (Collision-resistant Unique Identifier)
CUIDs are designed to be highly unique, focusing on being readable and less prone to collisions even in high-concurrency environments.
A Collision-resistant Unique Identifier (CUID) with 25 characters in base-36 encoding typically has a size of around 129 bits. This provides a substantial level of uniqueness while keeping the identifier relatively compact.
Example ID: cjld2cyuq0006s1rxy8123456
Pros:
- Highly unique with collision resistance even in high concurrency
- Suitable for distributed systems with high-traffic
- Fast generation, designed for high-concurrency environments
- Efficient storage, compact format
Cons:
- Slightly larger than simple numeric IDs
- More complex than simple numeric or auto-increment IDs
- Not naturally ordered, designed primarily for uniqueness
CUID implementation
- JavaScript (Browsers & Node)
- Ruby
- .NET Framework
- .NET
- Go
- PHP
- Elixir
- Haskell
- Python
- Clojure
- Java
- Lua
- Perl
- Perl 6
- OCaml
- Swift
- Insomnia
- Rust
- Racket
- Deno
- Crystal
- C
8. NanoID

NanoID is a tiny, secure, URL-friendly unique string ID generator that is designed to be more flexible and performant than UUID.
Example ID: V1StGXR8_Z5jdHi6B
Pros:
- Secure and highly unique with customizable size and alphabet
- Suitable for distributed systems, highly scalable
- Fast generation with high security
- Compact and efficient due to customizable length and alphabet
Cons:
- Slightly more complex generation than UUID
- Customizability might lead to misuse if not properly managed
- No inherent orderability
NanoID Implementation
9. Sonyflake

Sonyflake is a distributed unique ID generator inspired by Twitter Snowflake, optimized for 64-bit IDs, and designed to be more efficient for generating unique IDs in a single data center.
Example ID: 1132088477364927953
Pros:
- Highly unique with a low risk of collisions in a single data center
- Optimized for single data center deployment, highly scalable
- Fast generation with efficient use of 64-bit storage
- Time-ordered, useful for chronological sorting
- Efficient 64-bit size, similar to Twitter Snowflake
Cons:
- Requires careful configuration to avoid collisions
- Less suitable for multi-data center environments
- Limited to the single data center, it requires careful management
Sonyflake Implementation
10. FlakeID

FlakeID is a decentralized unique ID generator that creates 128-bit IDs based on timestamps, machine IDs, and random numbers.
Flake IDs have 128-bit size:
- 64-bit timestamp - milliseconds since the epoch (Jan 1, 1970)
- 48-bit worker ID - MAC address from a configurable device
- 16-bit sequence # - usually 0, incremented when more than one ID is requested in the same millisecond and reset to 0 when the clock ticks forward
Example ID: 4zqG3B2TnMs57S1PvQ
Pros:
- Combines timestamp, machine ID, and randomness for high uniqueness
- Suitable for distributed systems, highly scalable
- Fast generation, ideal for high-throughput systems
- Roughly ordered based on timestamp
- Larger 128-bit size balances uniqueness and orderability
Cons:
- Requires careful management of machine IDs and random components
- Larger storage size compared to simpler numeric IDs
- Not precisely ordered due to random component
FlakeID Implementation
11. Base62
Base62 encoding is a method of encoding IDs that combines uppercase and lowercase letters and digits, making it URL-friendly and compact. The size of Base62 of length 22 characters =22×5.95≈130.9-bit
Example ID: 1B2M2Y8AsgTpgAmY7PhCfg
Pros:
- Unique and URL-friendly avoid special characters
- Suitable for web applications needing URL-friendly IDs
- Fast generation with compact encoding
- Compact storage due to Base62 encoding
Cons:
- Not inherently collision-resistant in high-concurrency environments
- Requires careful management to ensure uniqueness
- Complexity in encoding and decoding compared to numeric IDs
- No inherent orderability
Base62 implementation
Summary
When selecting a unique identifier format for your application, consider the specific requirements, including uniqueness, scalability, performance, orderability, and storage efficiency. Each type of identifier has its tradeoffs, and the best choice will depend on your application's context.
- Database Auto-Increment: Simple and efficient for single-node applications, but not suitable for distributed systems.
- Twitter Snowflake: Best for high-throughput, time-ordered IDs in distributed systems.
- UUID: Ideal for global uniqueness without central coordination but with larger storage needs.
- ULID: Combines timestamp-based ordering with global uniqueness, suitable for sortable IDs.
- KSUID: Offers sortable IDs with additional robustness from a checksum, though with larger storage requirements.
- MongoDB ObjectID: A balanced approach for systems needing roughly ordered IDs with reasonable storage efficiency.
- CUID: Best for high-concurrency environments needing collision resistance.
- NanoID: Ideal for secure, URL-friendly unique IDs with customizable length.
- Sonyflake: Optimized for single data center deployment with efficient 64-bit IDs.
- FlakeID: Suitable for distributed systems needing 128-bit unique IDs.
- Base62: Compact, URL-friendly IDs for web applications needing readable IDs.
By understanding these tradeoffs, you can make an informed decision that aligns with your application's needs for uniqueness, performance, and simplicity.